
Introduction to Reward-Guided Speculative Decoding (RSD)
Recently, large language models (LLMs) have made great strides in understanding and reasoning. However, generating responses one piece at a time can be slow and energy-intensive. This is especially challenging in real-world applications where speed and cost matter. Traditional methods often require a lot of computing power, making them inefficient. To tackle these issues, researchers are looking for new ways to cut down on costs while maintaining accuracy.
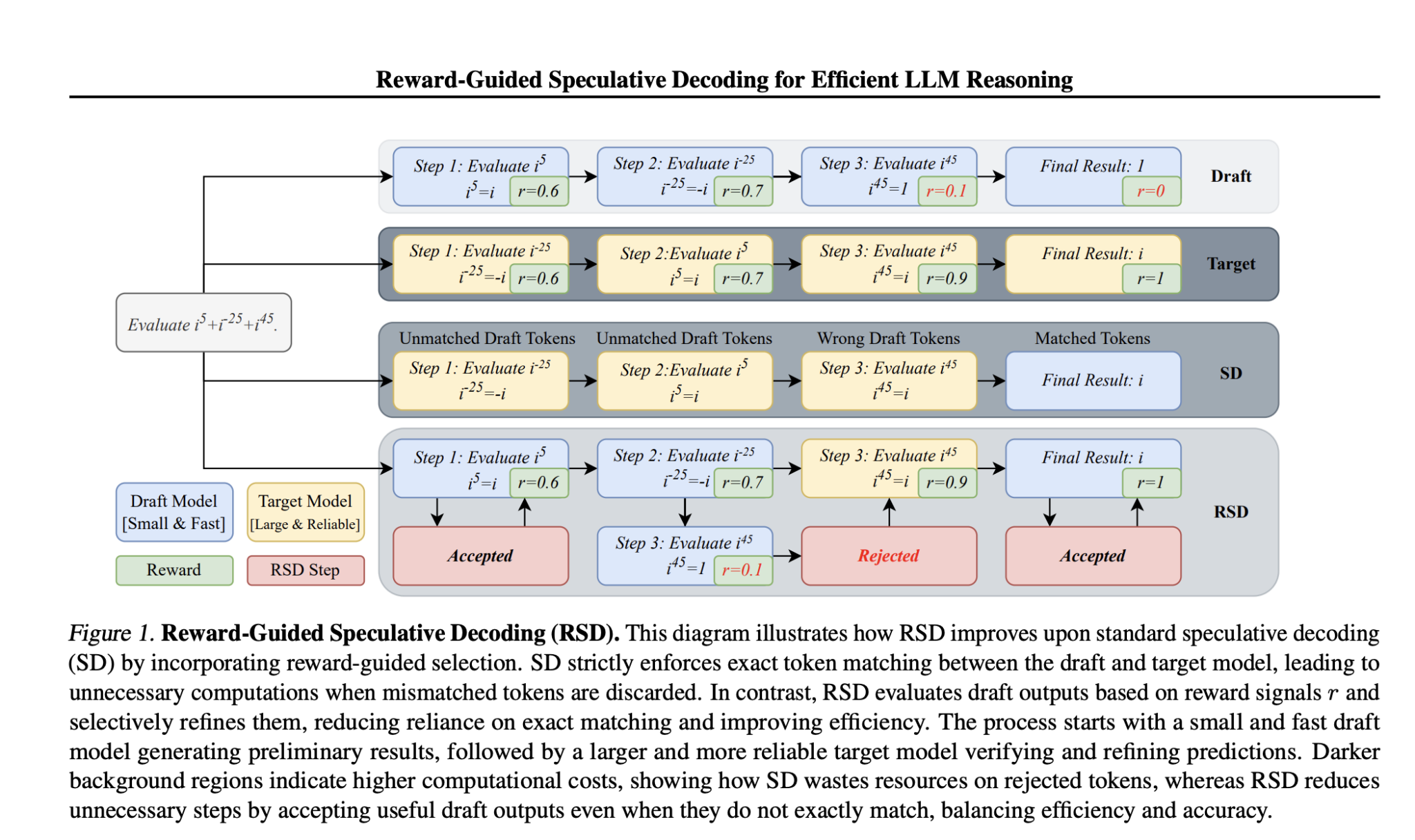
What is RSD?
Salesforce AI Research has introduced a new method called Reward-Guided Speculative Decoding (RSD). This approach uses two models: a quick, lightweight “draft” model and a more powerful “target” model. The draft model quickly generates initial responses, while a reward model checks their quality in real-time. RSD allows for a controlled bias towards better outputs, reducing unnecessary computations and speeding up the process.
Technical Details and Benefits of RSD
RSD works by having the draft model create candidate responses at a low cost. Each response is evaluated using a reward function. If a response meets a certain quality threshold, it is accepted; if not, the target model refines it. This method saves computing power by only using the target model when necessary. Key benefits include:
- Speed: RSD can be up to 4.4 times faster than using the target model alone.
- Accuracy: It often improves accuracy by an average of 3.5 points compared to traditional methods.
RSD effectively balances efficiency and quality, making it suitable for various applications.
Insights from RSD
Tests show that RSD performs exceptionally well on challenging benchmarks. For example, on the MATH500 dataset, RSD achieved an accuracy of 88.0 with a 72B target model and a 7B reward model, outperforming the target model alone. This method not only reduces computational load but also enhances reasoning accuracy.
Conclusion: A New Standard for LLM Inference
RSD represents a major advancement in efficient LLM inference. By combining a lightweight draft model with a powerful target model and using a reward-based system, RSD addresses both cost and quality challenges. With results showing significant speed and accuracy improvements, RSD sets a new benchmark for hybrid decoding frameworks.
Explore More
Check out the Paper and GitHub Page. Follow us on Twitter and join our 75k+ ML SubReddit.
Transform Your Business with AI
To stay competitive, consider implementing RSD in your operations:
- Identify Automation Opportunities: Find customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.
























