
Challenges in Generative AI
Generative AI faces a significant challenge in balancing autonomy and controllability. While advancements in generative models have improved autonomy, controllability remains a key focus for researchers. Text-based control is particularly important, as natural language provides an intuitive interface between humans and machines. This has led to impressive applications in areas such as image editing, audio synthesis, and video generation.
Issues in Low-Resource Scenarios
However, challenges arise in low-resource situations where obtaining sufficient text-paired data is costly or complex. Critical domains like molecular data, motion capture, and time series often lack adequate text labels, limiting supervised learning capabilities and hindering the deployment of advanced generative models. These limitations can lead to poor generation quality, model overfitting, bias, and restricted output diversity.
Current Mitigation Approaches
Several approaches have been proposed to address these issues, each with its limitations:
- Data augmentation techniques often misalign synthetic data with original text descriptions and may increase computational demands.
- Semi-supervised learning struggles with ambiguities in textual data, complicating the interpretation of unlabeled samples.
- Transfer learning can suffer from catastrophic forgetting, where the model loses previously acquired knowledge when adapting to new text descriptions.
Introducing Text2Data
Researchers from Salesforce AI Research have developed Text2Data, a diffusion-based framework that enhances text-to-data controllability in low-resource scenarios through a two-stage approach:
- Mastering data distribution using unlabeled data via an unsupervised diffusion model.
- Implementing controllable fine-tuning on text-labeled data without expanding the training dataset.
This framework effectively utilizes both labeled and unlabeled data to maintain fine-grained data distribution while achieving superior controllability.
How Text2Data Works
Text2Data operates in two distinct phases:
- It learns the marginal distribution using abundant unlabeled data.
- It fine-tunes parameters using labeled data while implementing constraint optimization to prevent catastrophic forgetting.
This approach ensures the model retains knowledge of the overall data distribution while gaining text controllability.
Key Components of Text2Data
Text2Data employs classifier-free diffusion guidance and optimizes three key components:
- L1(θ) for general data distribution learning.
- L’1(θ) for distribution preservation on labeled data.
- L2(θ) for text-conditioned generation.
The framework balances these objectives through a sophisticated update rule, allowing effective learning while preserving distribution knowledge.
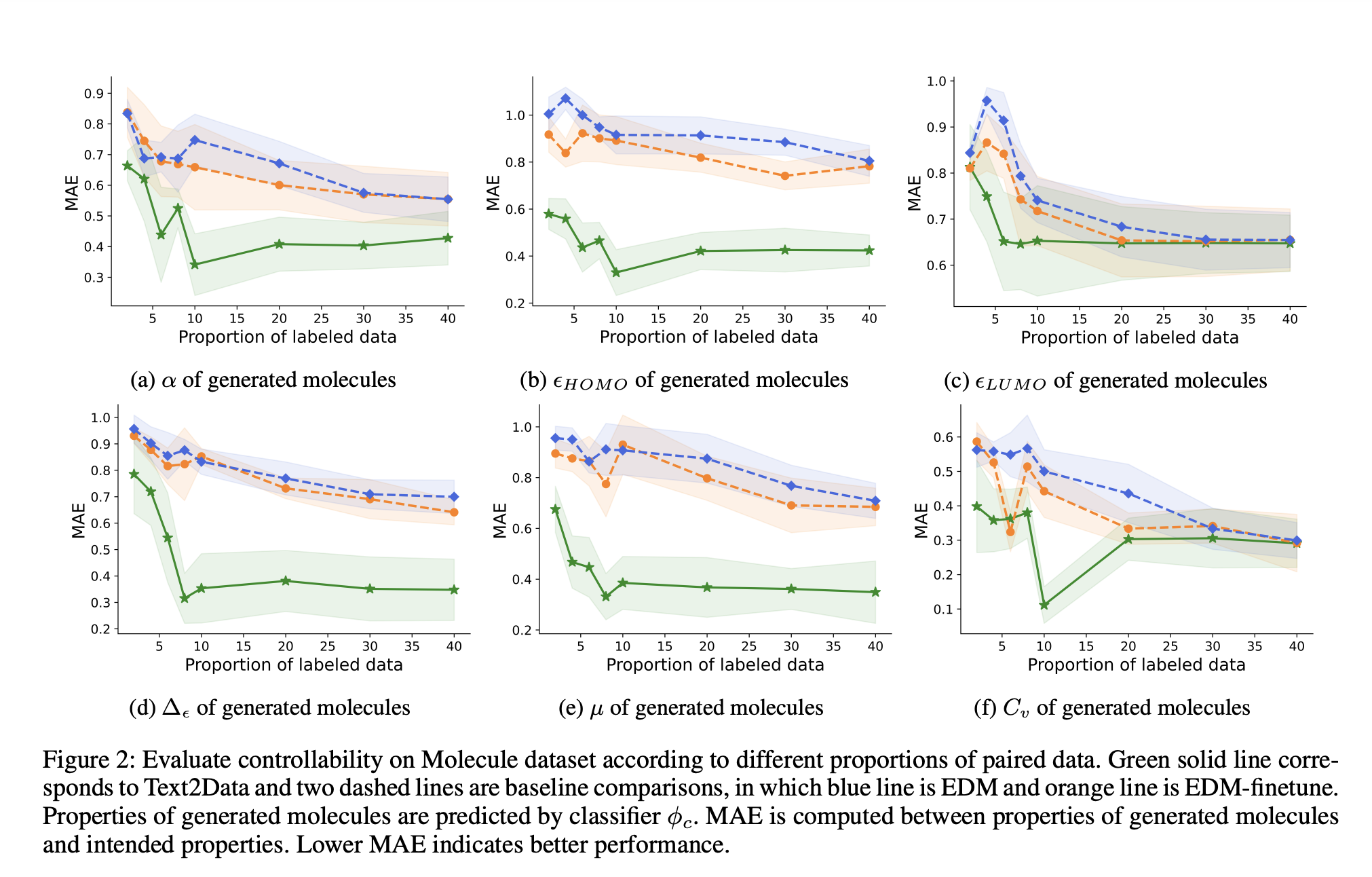
Validation and Results
Text2Data demonstrates superior controllability across multiple domains, achieving lower Mean Absolute Error (MAE) in molecular generation and surpassing baseline methods in motion and time series generation. It maintains exceptional generation quality, validating its effectiveness in mitigating catastrophic forgetting.
Conclusion
Text2Data effectively addresses the challenges of text-to-data generation in low-resource scenarios. By leveraging unlabeled data and implementing constraint optimization during fine-tuning, it successfully balances controllability with distribution preservation. This framework can be adapted to other generative architectures, showcasing its versatility.
Further Exploration
Explore how artificial intelligence can transform your business processes. Identify key performance indicators (KPIs) to measure the impact of your AI investments, select customizable tools, and start with small projects to gradually expand your AI usage.
For guidance on managing AI in business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.
























