
Understanding Language Models and Test-Time Scaling
Language models (LMs) have evolved rapidly due to advancements in computational power and large-scale training methods. Recently, a new technique called test-time scaling has emerged, which focuses on improving model performance during the inference stage by increasing computational resources.
Key Highlights:
- OpenAI’s o1 Model: Demonstrated enhanced reasoning by using test-time compute scaling.
- Challenges in Replication: Attempts to reproduce these results using various methods like Monte Carlo Tree Search (MCTS) have faced difficulties.
Innovative Solutions for Test-Time Scaling
Researchers have developed several methods to address the challenges of test-time scaling. Methods such as sequential scaling allow models to build on prior results through multiple attempts. Tree-based search techniques combine sequential and parallel scaling for improved performance.
Notable Approaches:
- REBASE: Uses a reward model to enhance tree search efficiency, outperforming traditional methods.
- Reward Models: Essential for evaluating both complete solutions and individual reasoning steps.
A Streamlined Approach to AI Training
New insights from Stanford University and other institutions have led to a simplified method for achieving test-time scaling. This involves two major innovations:
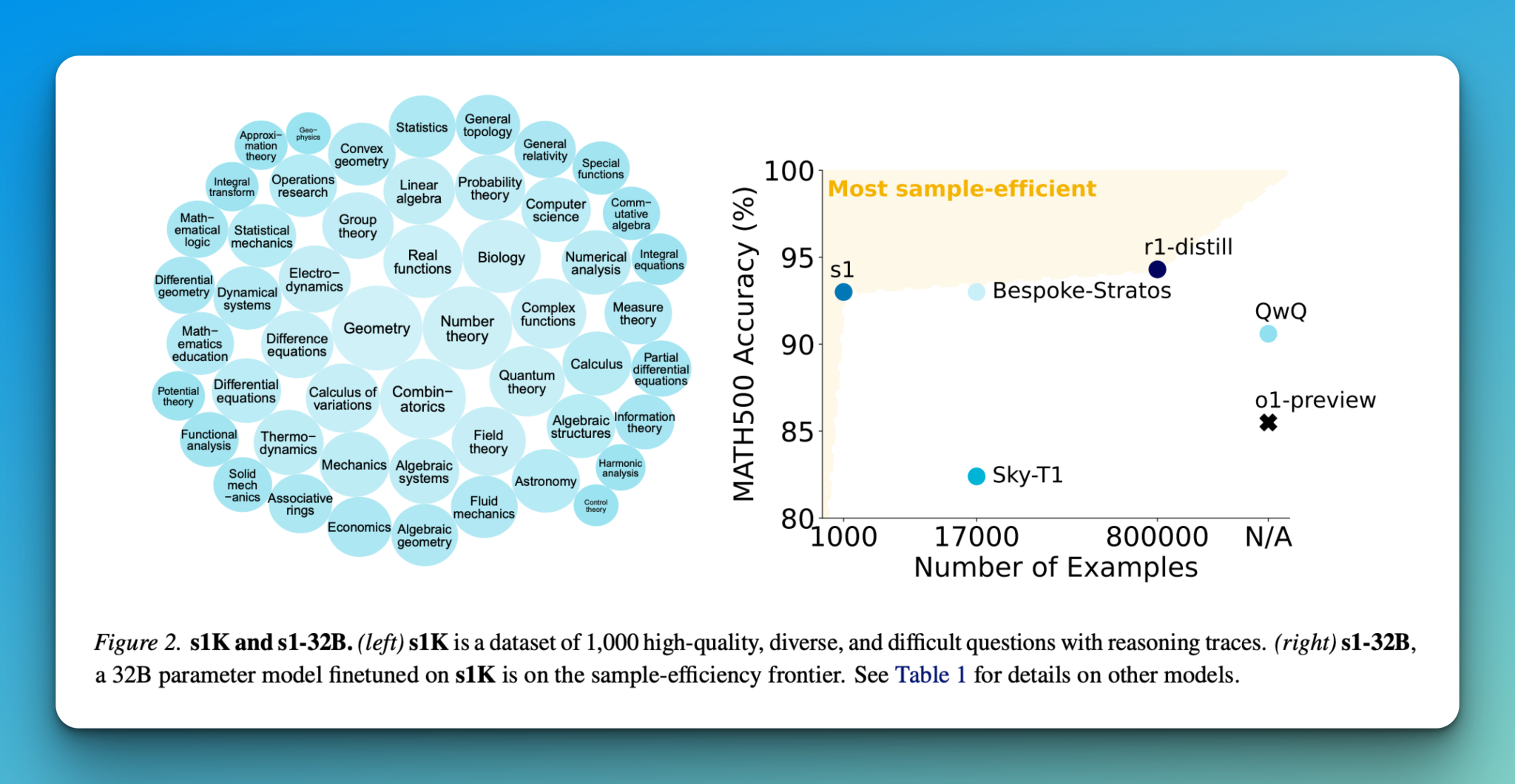
- s1K Dataset: A collection of 1,000 diverse and high-quality questions designed to enhance reasoning abilities.
- Budget Forcing: A technique that manages computational time by allowing models to pause and refine their reasoning.
Data Selection Process:
The selection of training data involves rigorous filtering based on quality, difficulty, and diversity, resulting in a final dataset of 1,000 questions across various domains.
Performance Improvements with s1-32B Model
The s1-32B model shows impressive gains in performance through test-time compute scaling. It effectively uses budget forcing to optimize its reasoning capabilities and stands out for its efficiency.
Key Performance Metrics:
- Sample Efficiency: s1-32B demonstrates significant improvement over the base model using only 1,000 additional training samples.
- Comparison with Other Models: While r1-32B performs well, it requires substantially more training data.
Implications for AI Solutions
This research indicates that fine-tuning with a limited dataset can produce highly competitive reasoning models. The budget forcing technique effectively replicates OpenAI’s successful test-time scaling behavior, showing that minimal training data can yield powerful AI capabilities.
Transform Your Business with AI:
- Identify Automation Opportunities: Streamline customer interactions using AI.
- Define KPIs: Ensure measurable impact from AI initiatives.
- Select AI Solutions: Choose tailored tools that meet your specific needs.
- Gradual Implementation: Start small, collect data, and expand AI applications wisely.
For more insights on leveraging AI for your business, connect with us at hello@itinai.com and follow us on Twitter and Telegram.
Explore More
Check out the full research paper and GitHub page for in-depth information. Join our community and stay updated on the latest in AI!

























