
Practical Solutions and Value of Reinforcement Learning with Execution Feedback in Code Synthesis
Overview:
Large Language Models (LLMs) use Natural Language Processing to generate code for tasks like software development. Improving alignment with input is crucial but computationally demanding.
Key Solutions:
- Developed a framework for continuous algorithm improvement to provide real-time feedback.
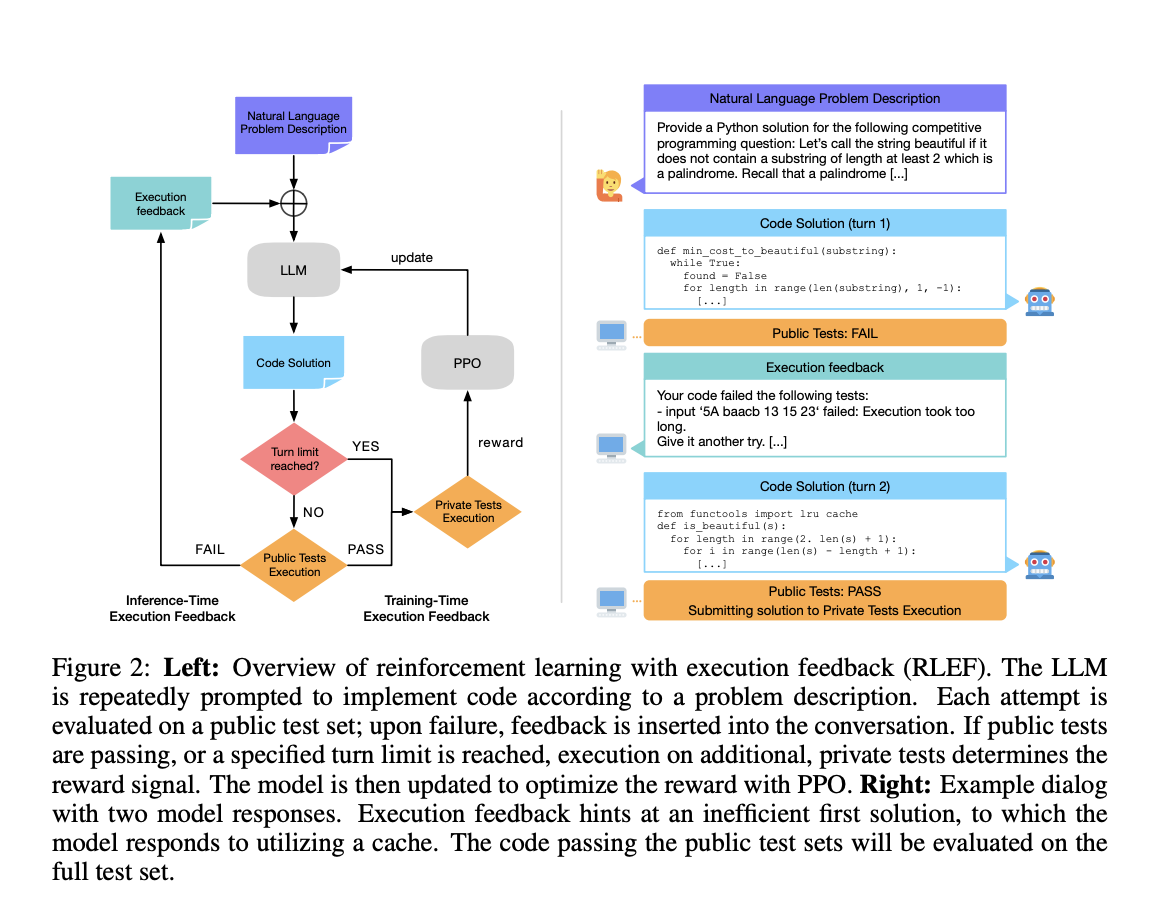
- Introduced a reinforcement learning framework for code augmentation and iterative feedback loop.
- Utilized Proximal Policy Optimization (PPO) for fine-tuning the algorithm’s behavior.
Value Proposition:
- Enhanced model performance in processing multi-turn conversations.
- Reduced computational time and error rates in code generation.
- Overcame challenges of supervised learning for more efficient and adaptive coding.
Conclusion:
Reinforcement Learning with Execution Feedback (RLEF) is a breakthrough for Large Language Models in code generation, offering flexibility and improved model effectiveness.
For AI KPI management advice, contact us at hello@itinai.com. Stay updated on AI insights via our Telegram channel or Twitter.
























