
ReZero: Enhancing Large Language Models with Reinforcement Learning
Introduction to Retrieval-Augmented Generation (RAG)
The field of Large Language Models (LLMs) has advanced significantly, particularly with the introduction of Retrieval-Augmented Generation (RAG). This innovative approach allows LLMs to access real-time information from databases and search engines, enhancing their ability to provide accurate and relevant responses in knowledge-intensive scenarios. However, as tasks become more complex, the interaction between LLMs and retrieval systems must improve to effectively address ambiguous or evolving information needs.
The Challenge of Query Quality
One of the primary challenges faced by LLMs that utilize retrieval mechanisms is their sensitivity to the quality of search queries. When an initial query fails to yield useful information, the system often lacks a strategy for recovery. This can result in the model either generating incorrect answers or terminating the search prematurely. Current methodologies typically assume that a single effective query is sufficient, overlooking the importance of persistence and retries in uncovering accurate information.
Innovative Solutions for Improved Interaction
To enhance the interaction between LLMs and external retrieval systems, several tools and techniques have been developed:
- Process Reward Models (PRMs): Reward intermediate reasoning improvements.
- Process Explanation Models (PEMs): Focus on the reasoning process.
- DeepRetrieval: Uses reinforcement learning to optimize query formulation.
- Iterative Techniques: Such as Self-Ask and IRCoT, which enable multi-step reasoning.
Despite these advancements, many systems do not encourage retrying or reformulating queries after a failed attempt, which is crucial for navigating complex information landscapes.
Introducing ReZero: A New Framework
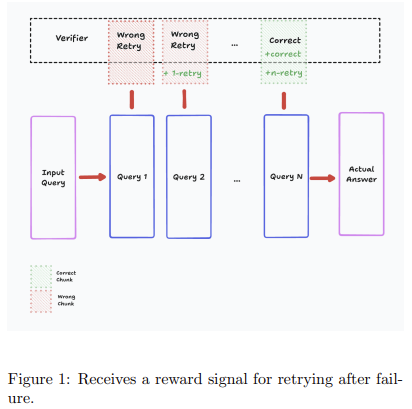
Researchers at Menlo have introduced a groundbreaking framework called ReZero, designed to teach LLMs to persist in their information searches by rewarding query retries. This framework operates on the principle that, similar to human behavior, when an initial search fails, it is rational to reformulate the query and attempt again. ReZero creates a learning environment where models receive positive feedback for recognizing failed searches and making subsequent attempts.
Technical Overview of ReZero
ReZero employs a reinforcement learning method known as Group Relative Policy Optimization (GRPO). This approach simplifies the training process by eliminating the need for a separate critic model. The model is trained using multiple reward functions, including:
- Correctness of the final answer
- Adherence to the required format
- Retrieval of relevant content
- Presence of a retry when necessary
These rewards are designed to ensure that retries lead to valid final answers, preventing unproductive query attempts. Additionally, the model is trained with noise in the search results to enhance its adaptability to real-world conditions.
Case Study: Apollo 3 Mission Dataset
The ReZero framework was evaluated using the Apollo 3 mission dataset, which was divided into 341 data chunks. The model was trained for approximately 1,000 steps on a single NVIDIA H200 GPU. The results were promising:
- ReZero achieved a peak accuracy of 46.88% at 250 training steps.
- The baseline model, without the retry reward, peaked at only 25.00% at 350 steps.
- Both models experienced a decline in performance after reaching their peak, indicating potential overfitting.
Key Takeaways from ReZero
- Enhances LLM search capabilities by rewarding retry behavior.
- Utilizes reinforcement learning through Group Relative Policy Optimization (GRPO).
- Incorporates multiple reward functions to ensure effective learning.
- Demonstrates significant improvements in accuracy compared to traditional models.
- Introduces persistence as a trainable behavior in retrieval-augmented systems.
Conclusion
The ReZero framework represents a significant advancement in the capabilities of LLMs, particularly in their ability to handle complex information retrieval tasks. By rewarding persistence and query retries, ReZero not only improves the accuracy of responses but also aligns LLM behavior more closely with human problem-solving strategies. As businesses increasingly adopt AI technologies, frameworks like ReZero can enhance decision-making processes and drive efficiency in information retrieval.

























