
Revolutionizing Recurrent Neural Networks RNNs: How Test-Time Training TTT Layers Outperform Transformers
Introduction
Self-attention mechanisms are excellent at processing extended contexts, but have high computational costs. Recurrent Neural Networks (RNNs) are computationally efficient but perform poorly in lengthy settings due to fixed-size representation constraints. This led researchers from Stanford University, UC San Diego, UC Berkeley, and Meta AI to propose Test-Time Training (TTT) layers, which combine expressive hidden states with linear complexity.
TTT Layers
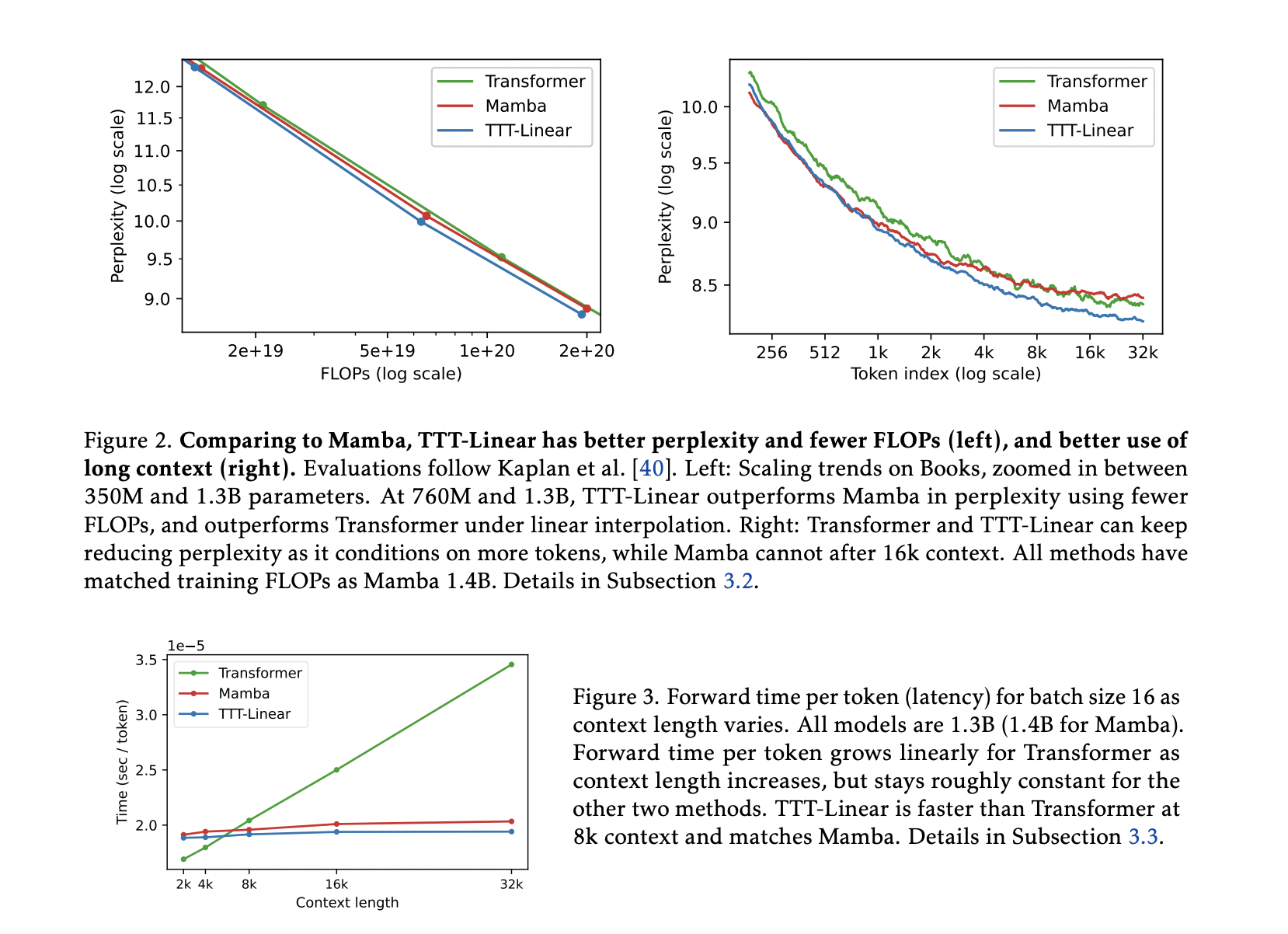
The TTT layers, including TTT-Linear and TTT-MLP, perform on par with or better than baselines, exhibiting effective usage of extended contexts. TTT-Linear has matched or outperformed Mamba in wall-clock time and beats the Transformer in speed for sequences up to 8,000 tokens.
Primary Contributions
The team introduced TTT layers, integrating a training loop into a layer’s forward pass, and showed that TTT-Linear outperforms both Transformers and Mamba. They also created mini-batch TTT and the dual form to enhance hardware efficiency, making TTT-Linear a useful building block for large language models.
For AI KPI management advice, connect with us at hello@itinai.com. For continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
Company Evolution with AI
Evolve your company with AI, stay competitive, and leverage the advantages of TTT Layers. Discover how AI can redefine your work, identify automation opportunities, define KPIs, select an AI solution, and implement gradually for business impact. Explore AI solutions at itinai.com.
























