
Introducing the Predibase Inference Engine
Predibase has launched the Predibase Inference Engine, a powerful platform designed for deploying fine-tuned small language models (SLMs). This engine enhances SLM performance by making deployments faster, scalable, and cost-effective for businesses.
Why the Predibase Inference Engine Matters
As AI becomes integral to business operations, deploying SLMs efficiently is increasingly challenging. Traditional infrastructures often lead to high costs and slow performance. The Predibase Inference Engine directly addresses these issues, providing a tailored solution for enterprise AI needs.
Join Us for a Webinar
Learn more about the Predibase Inference Engine by joining our webinar on October 29th.
Key Challenges in Deploying LLMs
Businesses face several obstacles when integrating AI, particularly with large language models (LLMs):
- Performance Bottlenecks: Many cloud GPUs struggle with variable workloads, leading to slow responses.
- Engineering Complexity: Managing open-source models requires significant resources and expertise.
- High Infrastructure Costs: High-performing GPUs are expensive and often underutilized.
The Predibase Inference Engine simplifies these challenges, offering an efficient, scalable infrastructure for SLM management.
Innovative Features of the Predibase Inference Engine
- LoRAX: Serve hundreds of fine-tuned SLMs on a single GPU, reducing costs and resource needs.
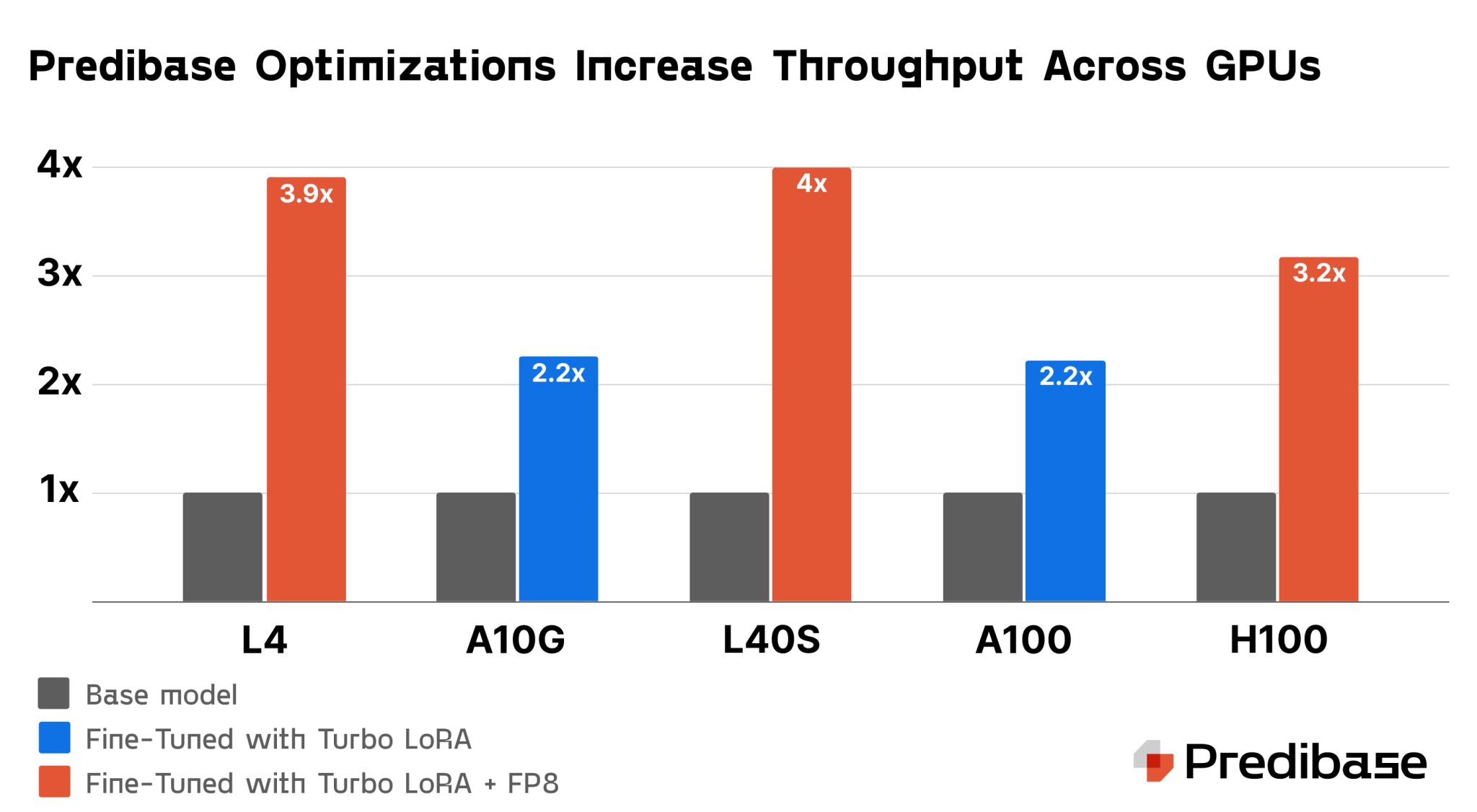
- Turbo LoRA: Increase throughput by 2-3 times while maintaining high response quality.
- FP8 Quantization: Cut memory use by 50%, allowing for up to double the throughput on GPUs.
- GPU Autoscaling: Adjust GPU resources in real-time based on demand, optimizing costs and performance.
Efficiently Scale Multiple Fine-Tuned SLMs
LoRAX allows for efficient deployment of multiple fine-tuned SLMs on a single GPU, significantly lowering costs. This innovative infrastructure optimizes memory use and maintains high throughput for concurrent requests.
Boosting Performance with Turbo LoRA and FP8
Turbo LoRA enhances SLM inference performance by predicting multiple tokens in one step, increasing throughput by 2-3 times. Coupled with FP8 quantization, this technique allows for more efficient processing and cost-effective deployments.
Optimized GPU Scaling
The Inference Engine dynamically adjusts GPU resources based on real-time demand, reducing costs and ensuring high performance. It also minimizes cold start times, enhancing system responsiveness during traffic spikes.
Enterprise-Ready Solutions
Predibase’s Inference Engine is designed for enterprise applications, offering features like VPC integration and multi-region availability. This simplifies AI workload management for businesses.
Customer Success Story
Giuseppe Romagnuolo, VP of AI at Convirza, shared, “The Predibase Inference Engine allows us to efficiently serve 60 adapters while maintaining an average response time of under two seconds.”
Flexible Deployment Options
Enterprises can deploy the Inference Engine within their own cloud or utilize Predibase’s managed SaaS platform. This flexibility ensures compliance with IT policies and security protocols.
Multi-Region High Availability
The Inference Engine guarantees uninterrupted service by automatically rerouting traffic and scaling resources during disruptions, ensuring consistent performance.
Real-Time Deployment Insights
Deployment Health Analytics provides real-time insights for monitoring and optimizing AI deployments. This tool helps businesses balance performance and cost efficiency effectively.
Why Choose Predibase?
Predibase offers unmatched infrastructure for serving fine-tuned LLMs, focusing on performance, scalability, and security. With built-in compliance and cost-effective solutions, Predibase is the ideal choice for enterprises looking to optimize their AI operations.
Ready to Transform Your AI Operations?
Visit Predibase.com to learn more about the Inference Engine or try it for free to see how our solutions can enhance your business.
If you want to evolve your company with AI, connect with us at hello@itinai.com or follow us for continuous insights on AI.

























