
<>
Practical Solutions and Value of RetrievalAttention in AI
Importance of RetrievalAttention
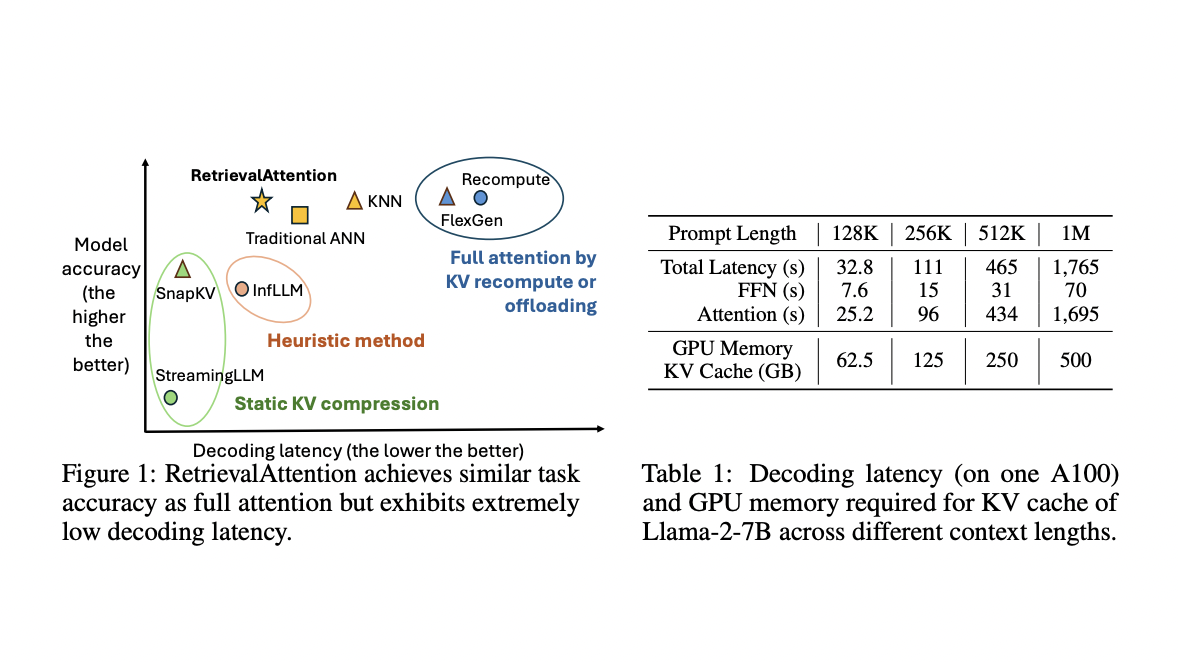
RetrievalAttention accelerates long-context LLM inference by optimizing GPU memory usage and employing dynamic sparse attention.
Key Features
– Utilizes dynamic sparse attention for efficient token generation
– Offloads most KV vectors to CPU memory
– Enhances accuracy and reduces computational costs
Benefits
RetrievalAttention achieves high accuracy, reduces latency, and enhances efficiency in complex tasks with long contexts.
Performance
Outperforms existing methods in accuracy and efficiency, achieving notable speedups and maintaining model accuracy.
Implementation
Uses CPU-GPU co-execution strategy to optimize attention computation, providing superior results compared to traditional methods.

























