
Practical Solutions for Large Language Model Training
Challenges in Language Model Training
Large language models (LLMs) face challenges such as compounding errors, exposure bias, and distribution shifts during iterative model application. These issues can lead to degraded performance and misalignment with human intent.
Approaches to Address Challenges
Existing approaches include behavioral cloning (BC), inverse reinforcement learning (IRL), and adversarial training methods. These methods aim to improve stability, scalability, and performance of language models.
Investigation of RL-based Optimization
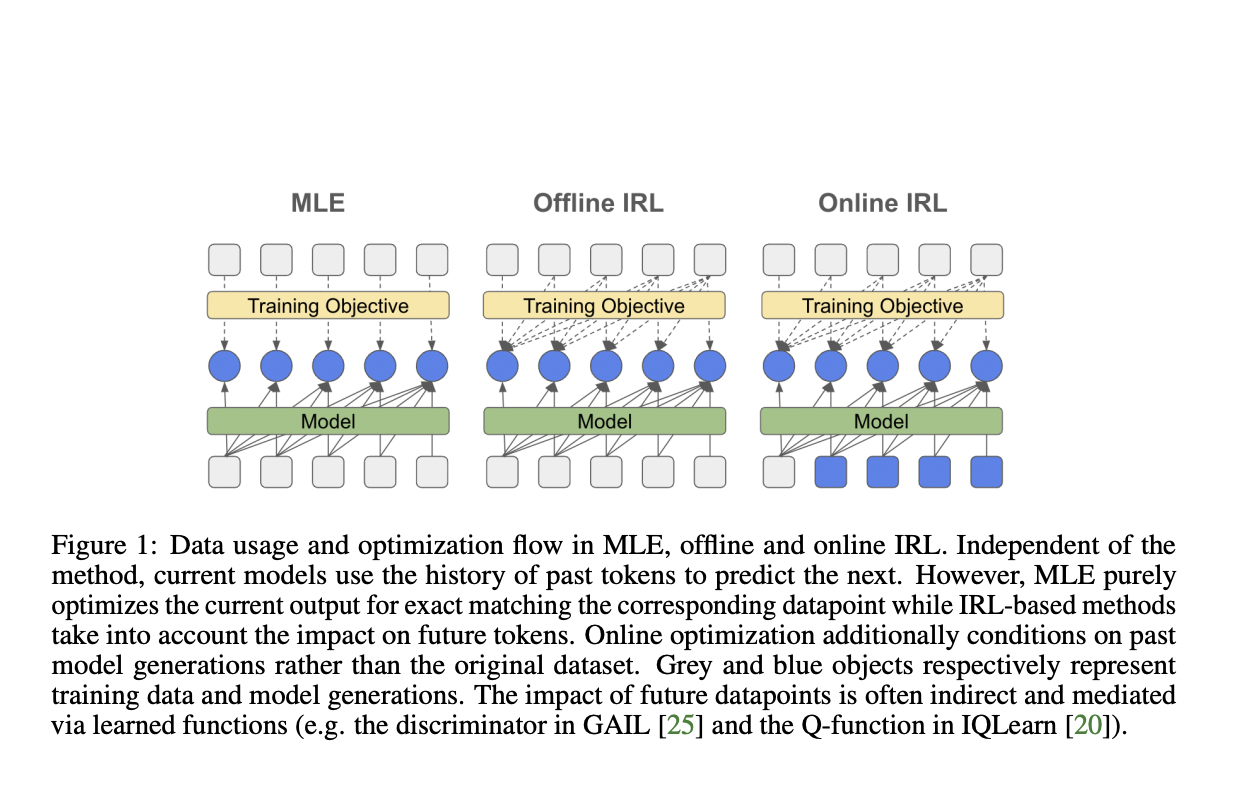
DeepMind researchers propose an investigation of RL-based optimization, particularly focusing on the distribution matching perspective of IRL, for fine-tuning large language models. This approach aims to provide an effective alternative to standard maximum likelihood estimation (MLE).
Unique Approach to Language Model Fine-Tuning
The proposed methodology introduces a unique approach to language model fine-tuning by reformulating inverse soft Q-learning as a temporal difference regularized extension of MLE. This method bridges the gap between MLE and algorithms that exploit the sequential nature of language generation.
Key Findings from Experiments
The researchers found that IRL methods, particularly IQLearn, showed performance improvements, enhanced diversity in model generations, and demonstrated scalability across different model sizes and architectures. Additionally, IQLearn achieved higher performance in low-temperature sampling regimes and reduced reliance on beam search during inference.
AI Solutions for Business
Discover how AI can redefine your way of work, redefine your sales processes, and customer engagement. Identify automation opportunities, define KPIs, select an AI solution, and implement gradually. Connect with us for AI KPI management advice and continuous insights into leveraging AI.
Evolve Your Company with AI
If you want to evolve your company with AI, stay competitive, and use Rethinking LLM Training: The Promise of Inverse Reinforcement Learning Techniques to your advantage.
























