
Introduction to ReMoE: A New AI Solution
The evolution of Transformer models has greatly improved artificial intelligence, achieving excellent results in various tasks. However, these improvements often require significant computing power, making scalability and efficiency challenging. A solution to this is the Sparsely Activated Mixture-of-Experts (MoE) architecture, which allows for greater model capacity without the same increase in computing costs. Traditional methods like TopK+Softmax routing in MoE models do, however, have limitations that affect scalability and expert usage.
What is ReMoE?
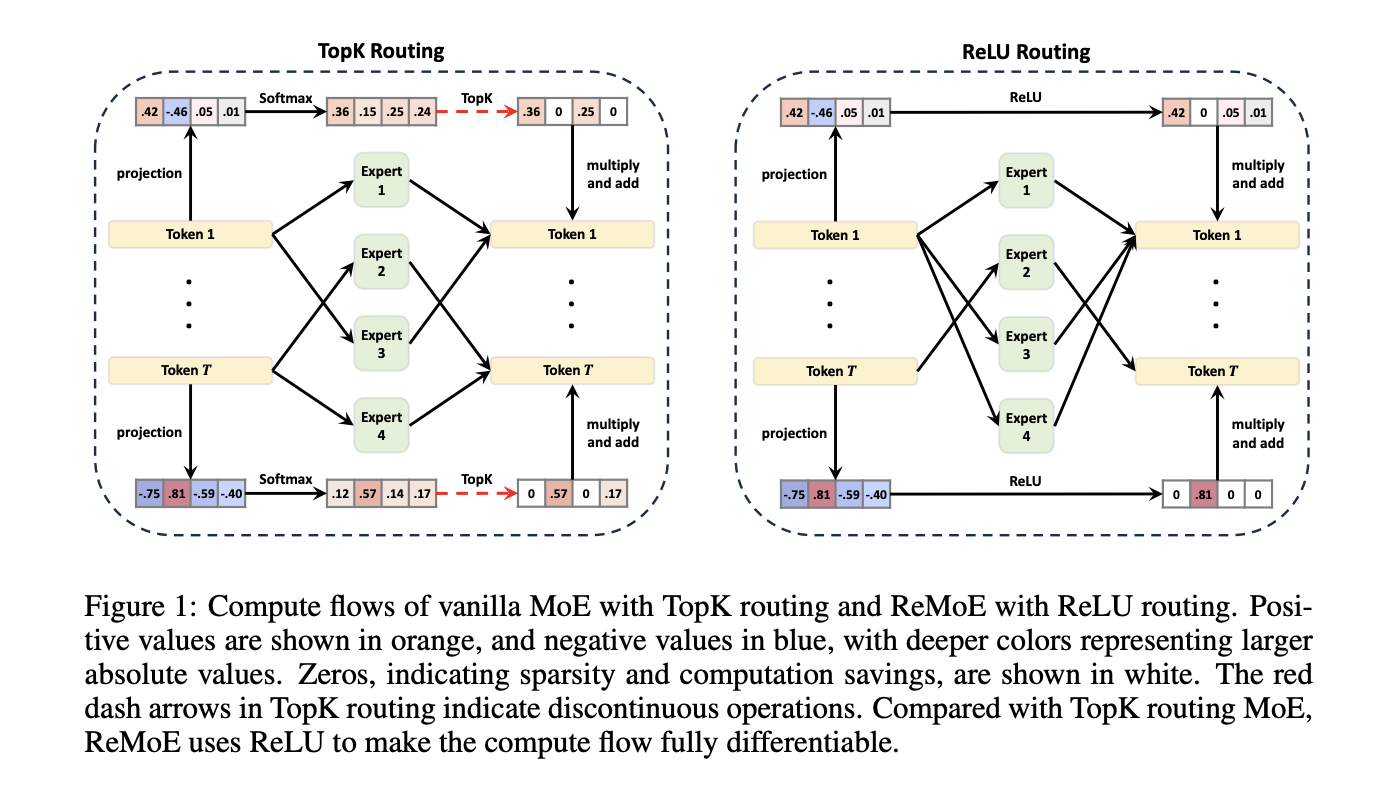
Researchers from Tsinghua University have introduced ReMoE (ReLU-based Mixture-of-Experts), which addresses the shortcomings of traditional MoE models. By replacing the TopK+Softmax routing with a ReLU-based system, ReMoE enables a fully differentiable routing process. This change simplifies the architecture and integrates easily with existing MoE models.
How ReMoE Works
ReMoE uses ReLU activation functions to dynamically manage which experts are active. Unlike TopK routing, which limits activation to a set number of experts, ReLU routing allows for smooth transitions between active and inactive states. The model uses adaptive L1 regularization to control the number of active experts, ensuring efficient computation without sacrificing performance.
Key Benefits of ReMoE
- Smoother Training: The continuous ReLU-based routing improves stability during training by avoiding sudden changes in expert activation.
- Dynamic Resource Allocation: ReMoE adjusts the number of active experts based on the complexity of the input, optimizing resource use.
- Balanced Expert Utilization: An adaptive load-balancing strategy ensures fair distribution of tasks among experts, enhancing performance.
- Scalability: ReMoE can handle more experts with finer control compared to traditional MoE models.
Experimental Insights
Research shows that ReMoE consistently outperforms traditional MoE setups. Testing with the LLaMA architecture revealed:
- Improved Performance: ReMoE shows lower validation loss and higher accuracy on various tasks.
- Scalability: Performance differences grow as the number of experts increases, proving ReMoE’s effectiveness.
- Efficient Resource Use: More complex tasks receive the necessary computational resources without excess waste.
Conclusion
ReMoE represents a significant step forward in Mixture-of-Experts architectures by overcoming the limitations of TopK+Softmax routing. Its innovative ReLU-based routing and adaptive techniques make it both efficient and versatile. This advancement showcases how revisiting foundational designs can lead to better scalability and performance in AI systems.
For more details, check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect on our LinkedIn Group. Don’t forget to join our 60k+ ML SubReddit.
Transform Your Business with AI
Stay competitive and leverage AI to enhance your operations:
- Identify Automation Opportunities: Find key interactions that could benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that meet your needs and allow customization.
- Implement Gradually: Start small, gather insights, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram at t.me/itinainews or Twitter at @itinaicom.
Discover how AI can reshape your sales processes and customer engagement at itinai.com.

























