
Practical Solutions and Value of MoE Architectures
Sparse Activation for Efficient Model Scaling
Mixture-of-experts (MoE) architectures use sparse activation to efficiently scale model sizes, preserving high training and inference efficiency.
Challenges and Innovations in MoE Architectures
Challenges such as optimizing non-differentiable, discrete objectives are addressed by innovations like the SMEAR architecture, which merges experts gently in the parameter space and achieves high efficiency.
Application in Transformer Models and Language Model Pre-training
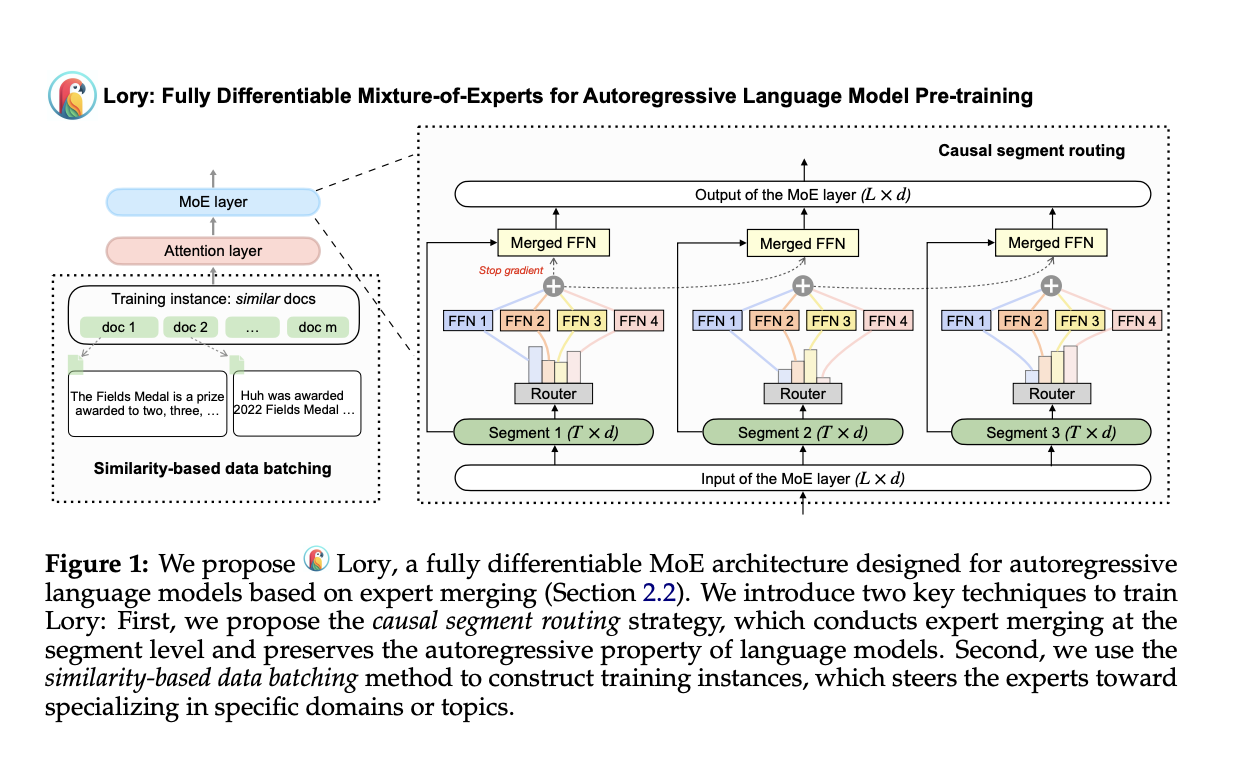
Sparsely activated MoE models are adapted into transformer models to improve performance in machine translation, and innovations like Lory from Princeton University and Meta AI scale MoE architectures to autoregressive language model pre-training.
Training Efficiency and Performance Results
Lory demonstrates outstanding results, achieving equivalent loss levels with fewer training tokens and outperforming dense baseline models in language modeling and downstream tasks.
Evolve Your Company with AI
If you want to evolve your company with AI, stay competitive, and benefit from innovations in MoE architectures, explore practical AI solutions to redefine your workflow and customer engagement.
Identify, Implement, and Optimize AI Solutions
Discover how AI can redefine your work processes by identifying automation opportunities, defining KPIs, selecting AI solutions, and implementing gradual integration for impactful business outcomes.
Practical AI Solution Spotlight: AI Sales Bot
Consider the AI Sales Bot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages, redefining sales processes and customer engagement.

























