
Introduction to FlashInfer
Large Language Models (LLMs) are essential in today’s AI tools, like chatbots and code generators. However, using these models has exposed inefficiencies in their performance. Traditional attention mechanisms, such as FlashAttention and SparseAttention, face challenges with different workloads and GPU limitations. These issues lead to high latency and memory problems, highlighting the need for a better solution for LLM inference.
What is FlashInfer?
FlashInfer is a new AI library developed by researchers from the University of Washington, NVIDIA, Perplexity AI, and Carnegie Mellon University. It is designed specifically for LLM inference, providing high-performance GPU implementations for various attention mechanisms. FlashInfer focuses on flexibility and efficiency, addressing the main challenges in LLM performance.
Key Features of FlashInfer
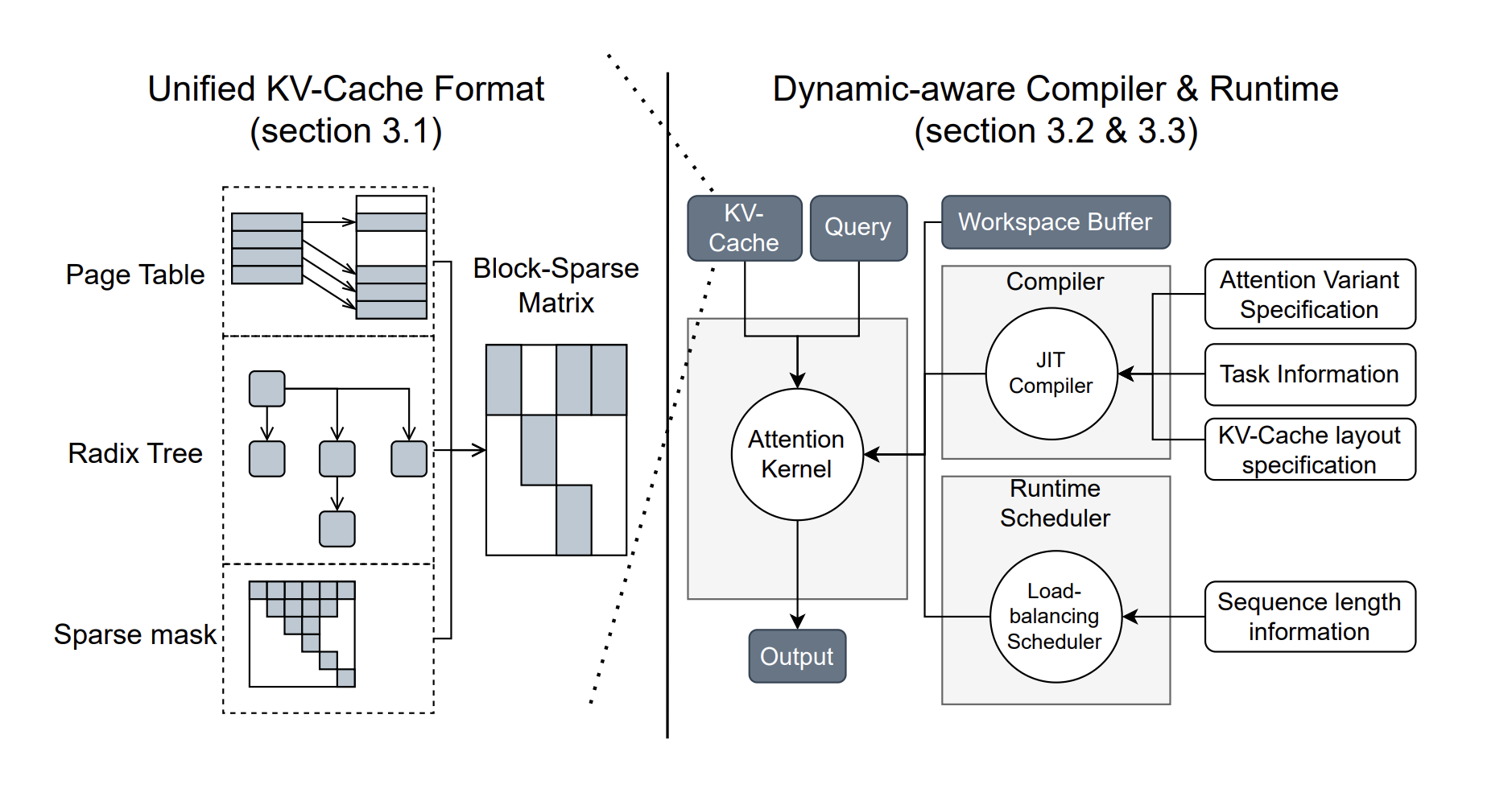
- Comprehensive Attention Kernels: Supports multiple attention types, enhancing performance for different scenarios.
- Optimized Shared-Prefix Decoding: Achieves significant speed improvements, making long prompt decoding faster.
- Dynamic Load-Balanced Scheduling: Adapts to input changes, maximizing GPU efficiency.
- Customizable JIT Compilation: Users can create and compile custom attention types for specific needs.
Performance Benefits
- Latency Reduction: Decreases inter-token latency by 29-69%, especially for long-context tasks.
- Throughput Improvements: Offers a 13-17% speedup on NVIDIA H100 GPUs for parallel tasks.
- Enhanced GPU Utilization: Improves performance in varied sequence lengths, ensuring better resource use.
Conclusion
FlashInfer is a powerful solution for LLM inference, providing significant performance and resource utilization improvements. Its flexible design and integration with existing frameworks make it a valuable asset for AI development. As an open-source project, it encourages collaboration and innovation in the AI community.
Get Involved
Check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. Join our 60k+ ML SubReddit for more insights.
Webinar Invitation
Join our webinar to learn how to enhance LLM model performance while ensuring data privacy.
Transform Your Business with AI
Stay competitive by leveraging AI solutions:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Measure the impact of your AI initiatives on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand your AI use responsibly.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.






















