
Practical AI Solutions with FlashAttention and INT-FlashAttention
FlashAttention for Efficient Attention Mechanism
FlashAttention optimizes attention computations by utilizing GPU memory hierarchy, resulting in faster performance and less memory overhead.
Combining Quantization with FlashAttention
Quantization methods like INT8 reduce data complexity, leading to faster processing and lower memory usage, especially in the inference stage.
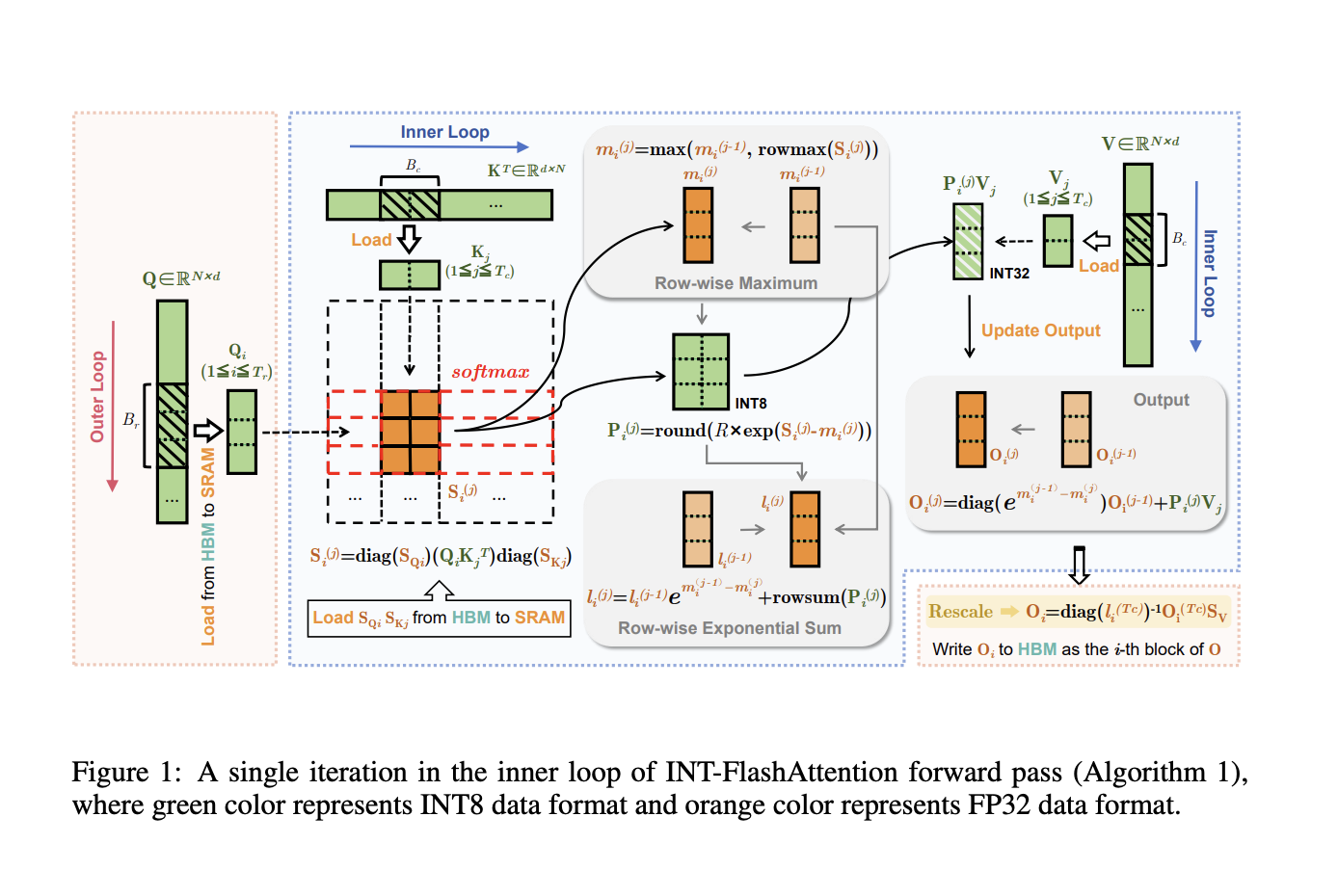
INT-FlashAttention Innovation
INT-FlashAttention integrates INT8 quantization with FlashAttention, boosting inference speed and energy efficiency significantly compared to traditional floating-point operations.
Key Benefits of INT-FlashAttention
INT-FlashAttention processes INT8 inputs efficiently, maintains accuracy with token-level quantization, and enhances scalability and efficiency of LLMs.
Enhancing Large Language Models with AI
Key Contributions of the Research Team
The team introduces INT-FlashAttention, an advanced quantization architecture improving efficiency without compromising attention mechanisms.
Advancement in Attention Computing
The implementation of INT-FlashAttention prototype in INT8 version signifies a major step in attention computing and quantization advancements.
Improving Inference Speed and Accuracy
INT-FlashAttention outperforms baseline solutions in terms of inference speed and quantization accuracy, showcasing its potential to enhance LLM efficiency.
Driving Efficiency with AI
INT-FlashAttention revolutionizes AI efficiency, making high-performance LLMs more accessible and effective, particularly on older GPU architectures like Ampere.
Embracing AI for Business Transformation
AI Implementation Strategy
Identify automation opportunities, define KPIs, select suitable AI solutions, and implement gradually to leverage AI for business growth.
Connect with Us for AI Solutions
For AI KPI management advice and insights into leveraging AI, reach out to us at hello@itinai.com or follow us on Telegram and Twitter.



























