
Enhancing Long-Sequence Modeling with ReMamba
Addressing the Challenge
In natural language processing (NLP), effectively handling long text sequences is crucial. Traditional transformer models excel in many tasks but face challenges with lengthy inputs due to computational complexity and memory costs.
Practical Solutions
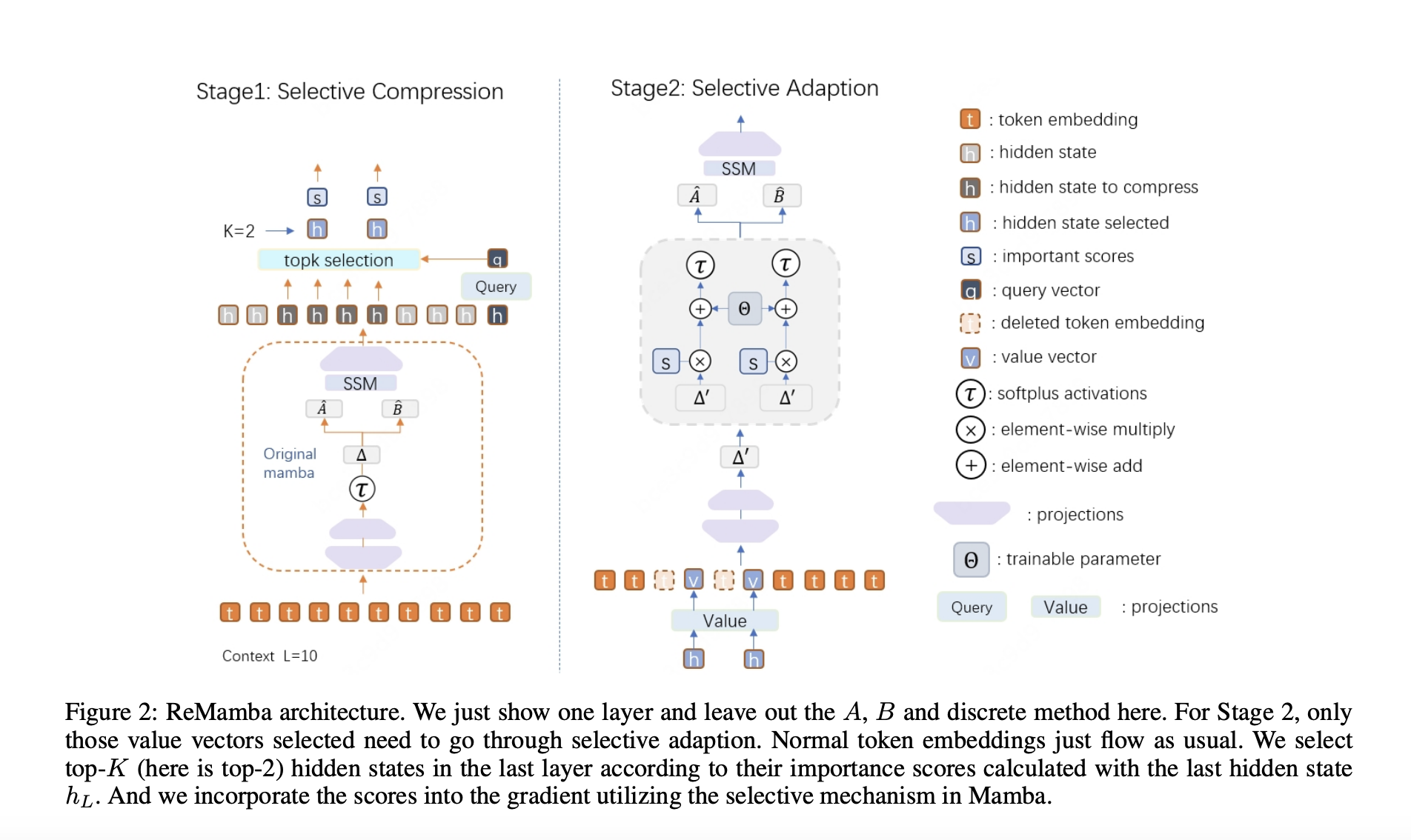
ReMamba introduces a selective compression technique within a two-stage re-forward process to retain critical information from long sequences without significantly increasing computational overhead. This approach enhances the model’s overall performance for long-context processing.
Value and Performance
Extensive experiments demonstrate that ReMamba outperforms the baseline Mamba model, achieving a 3.2-point improvement on the LongBench benchmark and a 1.6-point improvement on the L-Eval benchmark. It extends the effective context length to 6,000 tokens and maintains a significant speed advantage over traditional transformer models.
Future Developments
ReMamba not only offers a practical solution to the limitations of existing models but also sets the stage for future developments in long-context natural language processing. Its potential to enhance the capabilities of large language models is underscored by its performance on established benchmarks.
For more information, check out the Paper.
For AI KPI management advice, connect with us at hello@itinai.com.
Explore AI solutions at itinai.com.


























