
“`html
Practical AI Solutions for Reinforcement Learning
Proximal Policy Optimization (PPO) Challenges
Proximal Policy Optimization (PPO) is widely used in reinforcement learning (RL) applications, but its complex implementation and sensitivity to heuristics can hinder its effectiveness. Adapting PPO for modern generative models with billions of parameters raises concerns about its suitability for such tasks.
Policy Gradient (PG) Methods and Challenges
Policy Gradient (PG) methods are pivotal in RL, but computational challenges in methods like TRPO have led to approximations like PPO.
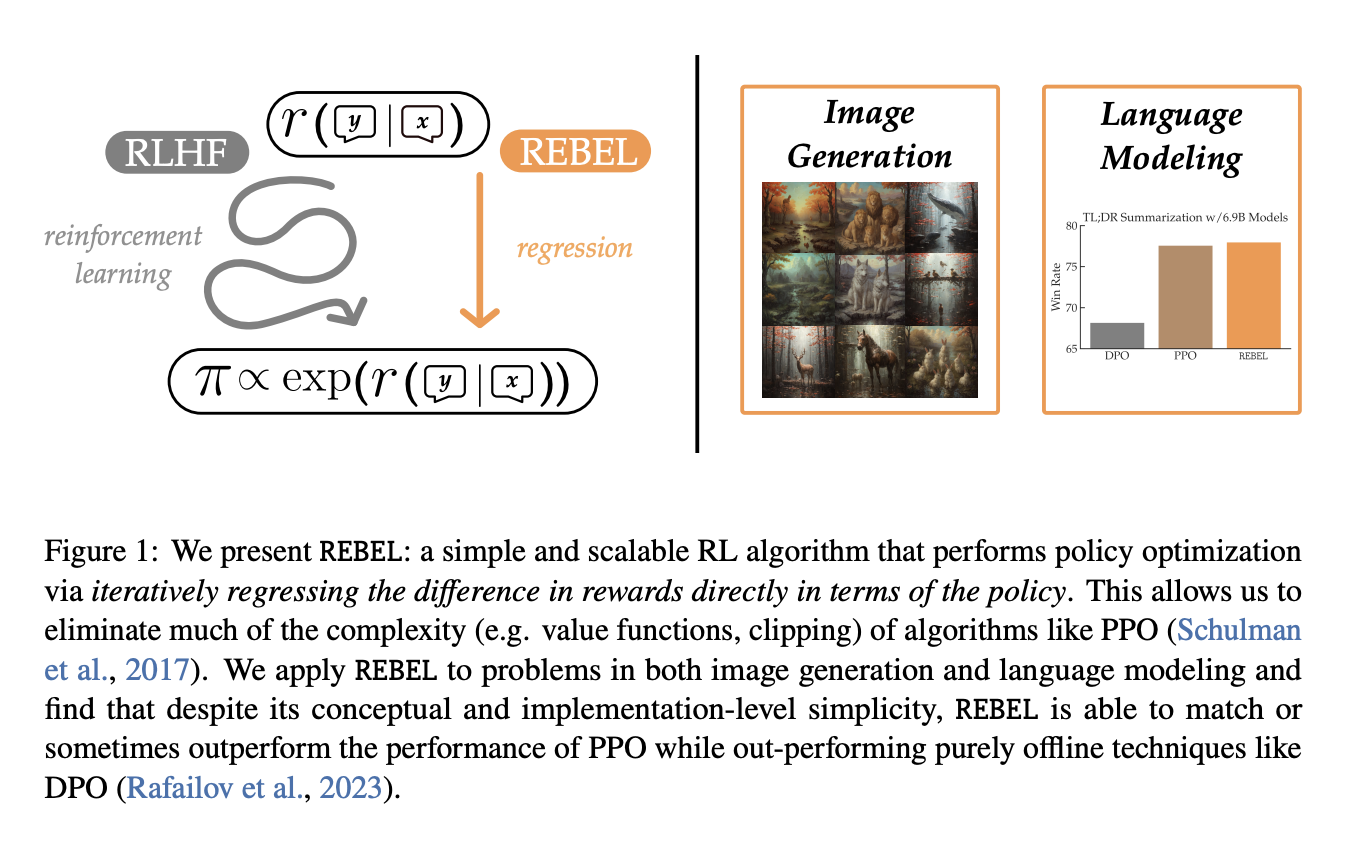
Introducing REBEL: A Simplified RL Algorithm
REBEL reduces the problem of policy optimization by regressing relative rewards, offering a lightweight implementation and strong theoretical guarantees for convergence and sample efficiency. It accommodates offline data and addresses common intransitive preferences.
REBEL’s Performance and Comparison
REBEL outperforms other models in terms of RM score and achieves a high win rate under GPT4, indicating its advantage in regressing relative rewards. It exhibits a trade-off between reward model score and KL divergence, showing competitive performance compared to other methods.
Practical Implementation and Scalability
REBEL focuses on driving down training error on a least squares problem, making it straightforward to implement and scale. It aligns with strong guarantees for RL algorithms and demonstrates competitive or superior performance in language modeling and guided image generation tasks.
Evolve Your Company with AI
Discover how AI, particularly REBEL, can redefine your work processes and identify automation opportunities, define KPIs, select AI solutions, and implement AI usage judiciously for business impact.
Spotlight on AI Sales Bot
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.
“`
























