
Revolutionizing Audio Interaction with Qwen2-Audio Model
Addressing Complex Audio Challenges with Precision and Versatile Interaction Capabilities
Audio holds immense potential for conveying complex information, driving the need for systems that can accurately interpret and respond to audio inputs. Qwen2-Audio is a groundbreaking audio-language model designed to overcome the limitations of traditional models and set a new standard for audio interaction systems.
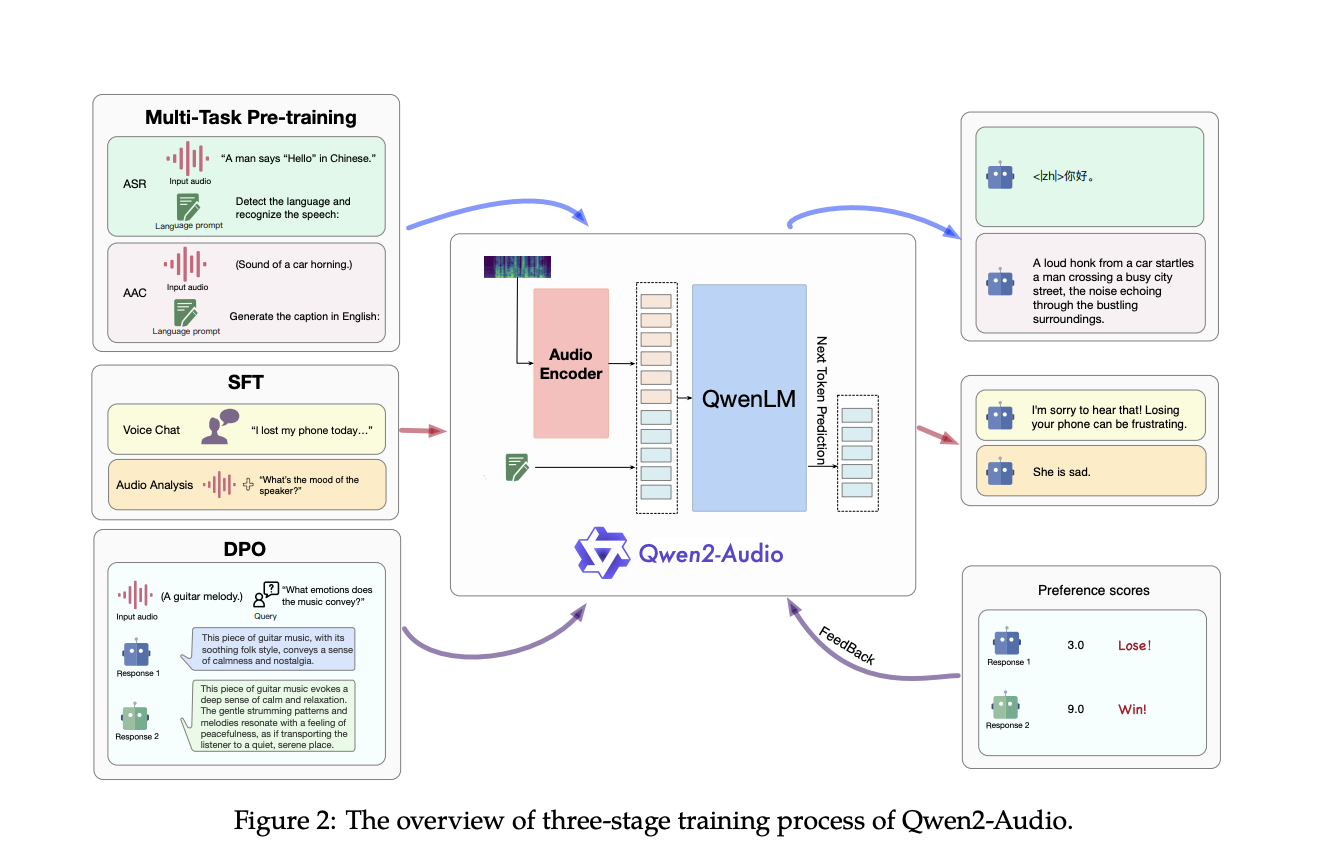
Qwen2-Audio simplifies the pre-training process, expands data volume, and integrates advanced architecture to handle various audio inputs, from simple speech to complex, multi-modal audio environments. The model excels in tasks such as Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), and Speech Emotion Recognition (SER), showcasing unmatched precision and versatility in audio interactions.
The model operates in Voice Chat and Audio Analysis modes, enabling free-form voice interactions and the analysis of various audio data based on user instructions. Qwen2-Audio seamlessly transitions between tasks without separate system prompts, enhancing its instruction-following capabilities.
Qwen2-Audio’s performance evaluations reveal its robustness, achieving impressive results across various benchmarks. The model’s potential to revolutionize how machines process and interact with audio signals makes it a valuable asset for businesses seeking to leverage AI to redefine their work processes and customer engagement.
To explore how Qwen2-Audio can redefine your company’s work processes and customer engagement, connect with us at hello@itinai.com. Follow us on Telegram and Twitter for continuous insights into leveraging AI.


























