Qwen Releases the Qwen2.5-VL-32B-Instruct: A Breakthrough in Vision-Language Models
In the rapidly evolving domain of artificial intelligence, vision-language models (VLMs) have become crucial tools that enable machines to interpret and generate insights from visual and textual data. However, achieving a balance between model performance and computational efficiency remains a significant challenge, especially in resource-constrained environments.
Introduction to Qwen2.5-VL-32B-Instruct
Qwen has recently launched the Qwen2.5-VL-32B-Instruct, a 32-billion-parameter model that outperforms its predecessor, the Qwen2.5-VL-72B, as well as comparable models like GPT-4o Mini. Released under the Apache 2.0 license, this model is a testament to Qwen’s commitment to open-source collaboration, catering to the growing demand for high-performing yet computationally efficient models.
Key Features of the Qwen2.5-VL-32B-Instruct
The Qwen2.5-VL-32B-Instruct model incorporates several advanced features:
- Visual Understanding: Excels in recognizing objects and analyzing various elements, including texts, charts, icons, and graphics within images.
- Agent Capabilities: Functions as a dynamic visual agent, capable of reasoning and directing tools for interaction on computers and smartphones.
- Video Comprehension: Understands videos longer than an hour, pinpointing relevant segments using advanced temporal localization.
- Object Localization: Accurately identifies objects in images, generating stable outputs for coordinates and attributes.
- Structured Output Generation: Supports structured outputs for data types such as invoices and tables, aiding applications in finance and commerce.
Performance Metrics
Empirical evaluations illustrate the model’s strengths:
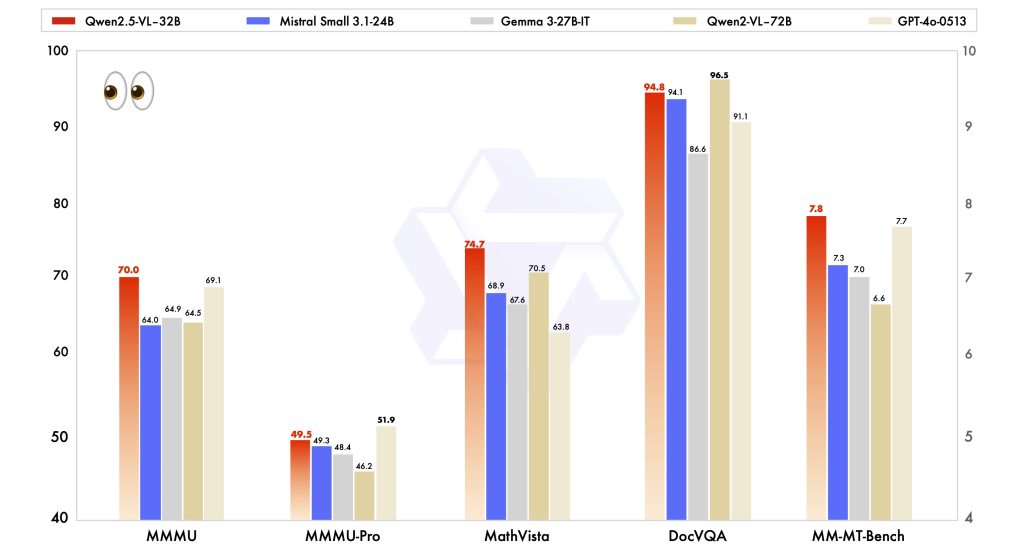
- Vision Tasks: Scored 70.0 on the Massive Multitask Language Understanding (MMMU) benchmark, surpassing Qwen2.5-VL-72B’s 64.5, and achieved significant improvements across various tasks like MathVista and OCR benchmarks.
- Text Tasks: Achieved strong performance scores of 78.4 on MMLU, 82.2 on MATH, and an impressive 91.5 on HumanEval, demonstrating competitive advantages over models like GPT-4o Mini.
Practical Business Solutions
Organizations looking to leverage AI can adopt the following strategies to integrate advanced models like Qwen2.5-VL-32B-Instruct:
- Identify Automation Opportunities: Assess current processes to find tasks where AI can add value, particularly in customer interactions.
- Establish KPIs: Define key performance indicators to measure the impact of AI investments on your business outcomes.
- Select Appropriate Tools: Choose AI tools that align with your business objectives while allowing for customization.
- Start Small: Initiate a pilot project, analyze its effectiveness, and then scale up AI applications gradually.
Conclusion
The Qwen2.5-VL-32B-Instruct marks a significant advancement in vision-language modeling, blending performance and efficiency effectively. Its open-source availability encourages exploration and innovation within the global AI community, paving the way for enhanced applications across various industries.
For further guidance on implementing AI in your business, feel free to reach out to us at hello@itinai.ru. Connect with us on Telegram, X, or LinkedIn.



