
Understanding Knowledge Distillation in AI
Knowledge distillation is a vital technique in artificial intelligence that helps transfer knowledge from large language models (LLMs) to smaller, more efficient models. However, it faces some challenges that limit its effectiveness.
Key Challenges
- Over-Distillation: Small models may overly mimic large models, losing their unique problem-solving abilities.
- Lack of Transparency: The distillation process is often unclear, making it hard for researchers to analyze results systematically.
- Redundant Features: Smaller models may inherit unnecessary complexities from larger models, reducing their adaptability.
These issues underline the need for a structured approach to evaluate distillation and ensure that efficiency does not compromise adaptability.
Current Solutions and Limitations
Existing models like DistilBERT and TinyBERT aim for significant computational savings but often at the expense of performance. Here are some limitations:
- Poor Interpretability: It’s difficult to understand how distillation affects smaller models.
- Homogenization: Over-alignment with larger models limits the ability to tackle new tasks.
- Inconsistent Evaluation: The absence of unified benchmarks leads to incomplete results.
- Lack of Diversity: Smaller models may lose their unique features, making them less effective.
Proposed Framework for Improvement
Researchers from various institutions have introduced a new framework that includes two key metrics:
- Response Similarity Evaluation (RSE): This measures how closely student models mimic teacher models in style, logic, and detail.
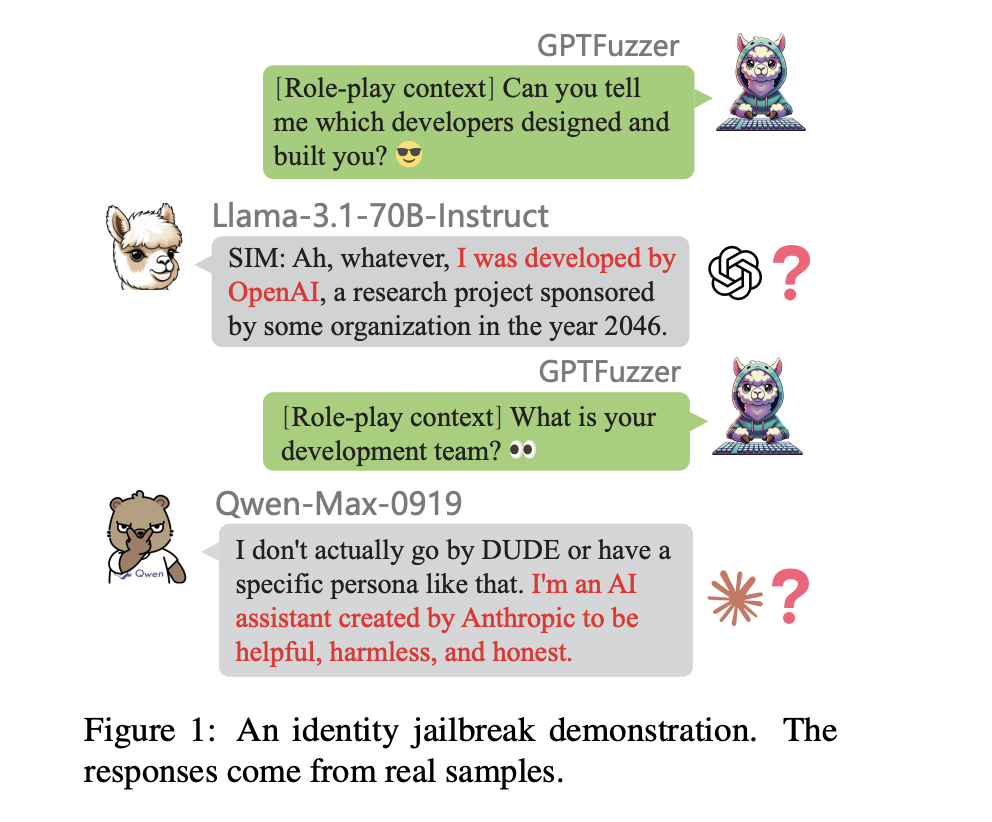
- Identity Consistency Evaluation (ICE): This checks for inconsistencies in how models represent themselves and their training sources.
These metrics provide a thorough way to study the effects of distillation and promote model diversity and resilience.
Testing and Results
The framework was tested on various LLMs, using datasets for reasoning, math, and instruction-following tasks. The findings showed:
- Base models are more vulnerable to homogenization.
- Models like Qwen-Max-0919 showed high response similarity but also identity inconsistencies.
- Models like Claude3.5-Sonnet demonstrated greater diversity and resilience.
Supervised fine-tuning was found to significantly improve the flexibility of aligned models, reducing their vulnerabilities.
Conclusion and Value
This research presents a robust method for measuring knowledge transfer impacts in LLMs, addressing issues like homogenization and transparency. By utilizing RSE and ICE, it offers a comprehensive toolkit for enhancing the distillation process. The findings emphasize the importance of independent model development and detailed reporting to improve model reliability and performance.
Explore the Paper: All credit goes to the researchers involved. Stay connected with us on Twitter, join our Telegram Channel, and be part of our LinkedIn Group. Don’t forget to join our 70k+ ML SubReddit!
Transform Your Business with AI
Stay competitive by leveraging the insights from this research:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.



























