
PyTorch Researchers Introduce an Optimized Triton FP8 GEMM (General Matrix-Matrix Multiply) Kernel TK-GEMM that Leverages SplitK Parallelization
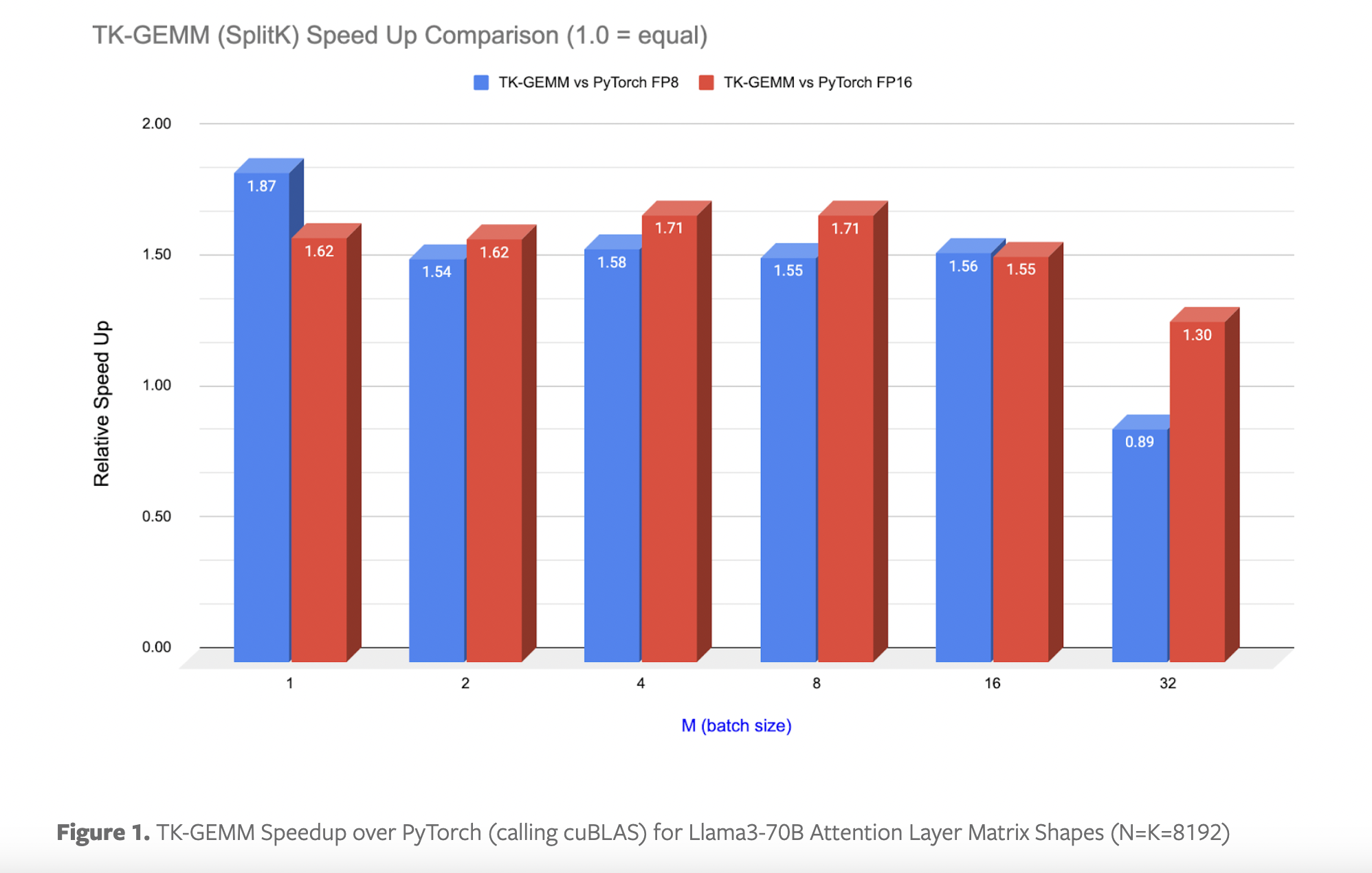
PyTorch introduced TK-GEMM, an optimized Triton FP8 GEMM kernel, to accelerate FP8 inference for large language models (LLMs) like Llama3 using Triton Kernels. Standard PyTorch execution often struggles with the overhead of launching multiple kernels on the GPU for each operation in LLMs, leading to inefficient inference. The researchers aim to overcome this limitation by leveraging SplitK parallelization to improve performance for Llama3-70B inference problem sizes on Nvidia H100 GPUs.
Key Benefits:
- Accelerated FP8 inference for large language models
- Improved performance for Llama3-70B inference problem sizes on Nvidia H100 GPUs
- Significant speedups over base Triton GEMM and cuBLAS FP8 and FP16
- Enhanced end-to-end speedup with CUDA graphs
Spotlight on a Practical AI Solution:
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.























