The Practical Solution: LongVILA for Long-Context Visual Language Models
Revolutionizing Long Video Processing
The challenge of enabling visual language models to process extensive contextual information in long video sequences can be addressed by LongVILA. This innovative approach offers a full-stack solution for long-context visual language models, enhancing efficiency and performance.
The Value of LongVILA
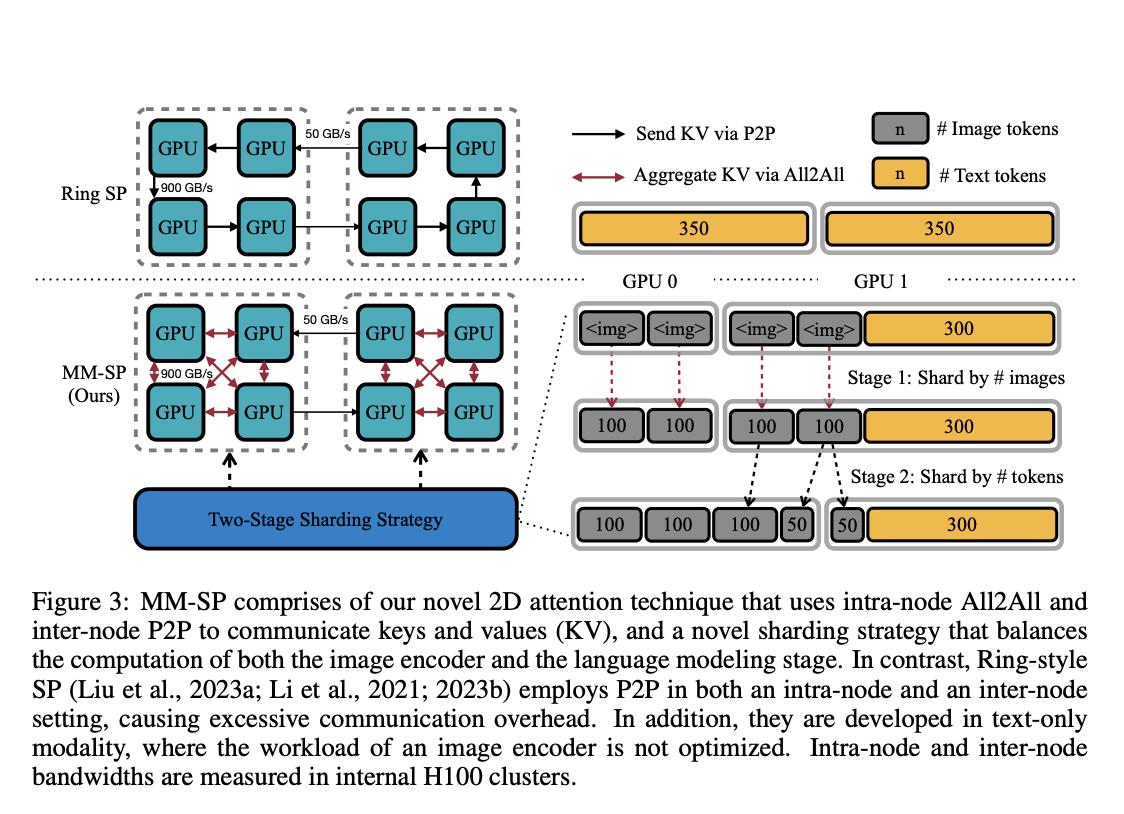
LongVILA introduces the Multi-Modal Sequence Parallelism (MM-SP) system, significantly enhancing the efficiency of long-context training and inference by enabling models to process sequences up to 2 million tokens in length using 256 GPUs. This system achieves substantial improvements in handling long video tasks, particularly in its ability to process extended sequences with high accuracy. The model consistently outperforms existing state-of-the-art models on benchmarks for video tasks of varying lengths, showcasing its superior ability to manage and analyze long video content effectively.
Implications for AI Advancement
LongVILA represents a significant advancement in the field of AI, particularly for tasks requiring long-context understanding in multi-modal settings. It sets a new standard for performance in long video tasks, marking a substantial contribution to the advancement of AI research.
Explore AI Opportunities
Discover how AI can redefine your way of work. Identify Automation Opportunities, Define KPIs, Select an AI Solution, and Implement Gradually. For AI KPI management advice and insights into leveraging AI, connect with us at hello@itinai.com. And for continuous insights into AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
Redefining Sales Processes and Customer Engagement
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.
























