
Orthogonal Paths: Simplifying Jailbreaks in Language Models
Practical Solutions and Value
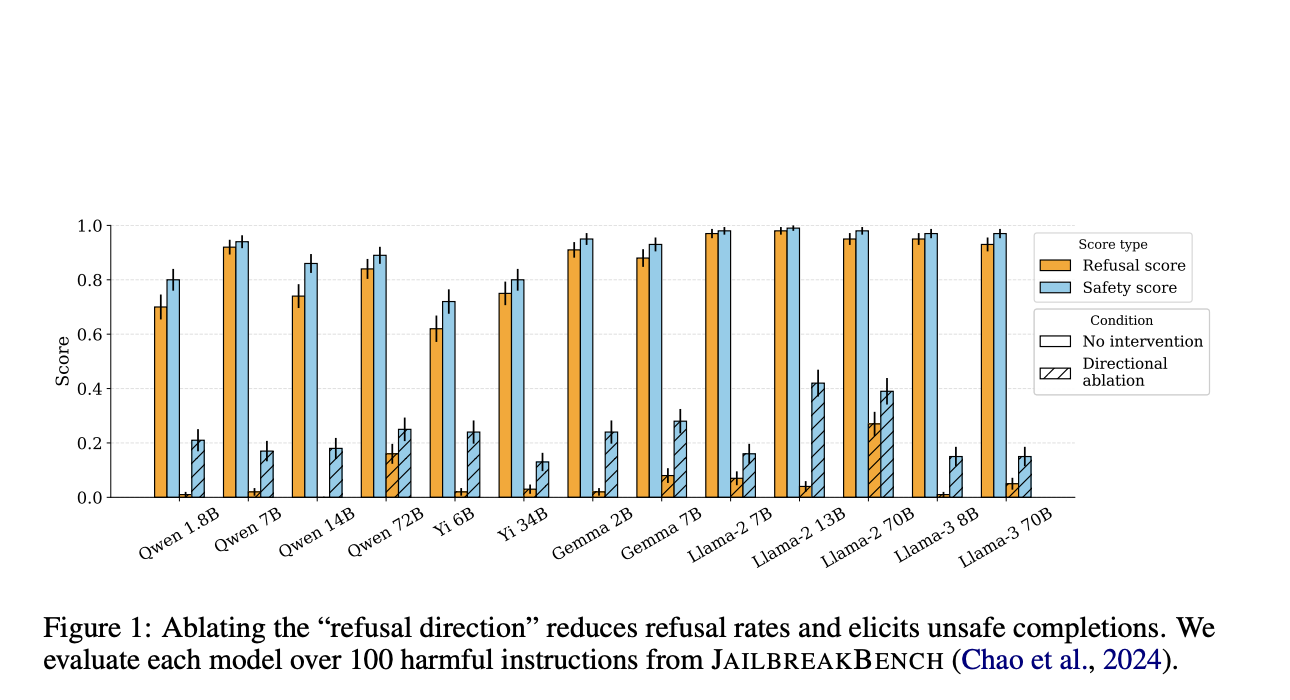
Ensuring the safety and ethical behavior of large language models (LLMs) in responding to user queries is crucial. This research introduces a novel method called “weight orthogonalization” to improve LLMs’ refusal capabilities, making them more robust and difficult to bypass.
The weight orthogonalization technique simplifies the process of jailbreaking LLMs and demonstrates high attack success rates across various models, highlighting a critical vulnerability in the safety mechanisms of LLMs.
For companies looking to evolve with AI, this research provides valuable insights into leveraging AI for automation opportunities, defining KPIs, selecting AI solutions, and implementing AI gradually to redefine sales processes and customer engagement.
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com and stay tuned on our Telegram or Twitter.

























