
Enhancing Reasoning Abilities of LLMs
Improving the reasoning capabilities of Large Language Models (LLMs) by optimizing their computational resources during testing is a significant research challenge. Current methods often involve fine-tuning models using search traces or reinforcement learning (RL) with binary rewards, which may not fully utilize available computational power. Recent studies indicate that increasing computational resources can enhance reasoning by generating longer solution traces and implementing structured steps like reflection, planning, and algorithmic search.
Challenges and Solutions
Key challenges include whether LLMs can effectively allocate computational resources based on the complexity of tasks and whether they can solve more difficult problems when given additional computational resources. Addressing these challenges is essential for improving efficiency and generalization in LLM reasoning.
Recent Advancements
Recent advancements have explored training separate verifiers for selection-based methods, such as best-of-N or beam search, which can be more effective than merely increasing data or model size. However, fine-tuning on unfamiliar search traces may lead to memorization rather than genuine improvements in reasoning. RL-based approaches have shown promise in generating chain-of-thought reasoning, allowing models to introspect and refine their outputs. Nevertheless, longer reasoning does not always correlate with higher accuracy, as models may produce unnecessarily long sequences without meaningful progress.
Innovative Approaches
To enhance efficiency, recent efforts have introduced structured reward mechanisms and penalties for excessive length, encouraging models to focus on producing concise, informative solutions. Researchers from Carnegie Mellon University and Hugging Face are investigating how to optimize test-time compute for LLMs by refining resource allocation during reasoning. They propose a fine-tuning approach that balances exploration and exploitation, ensuring consistent progress toward accurate answers.
Meta Reinforcement Learning Approach
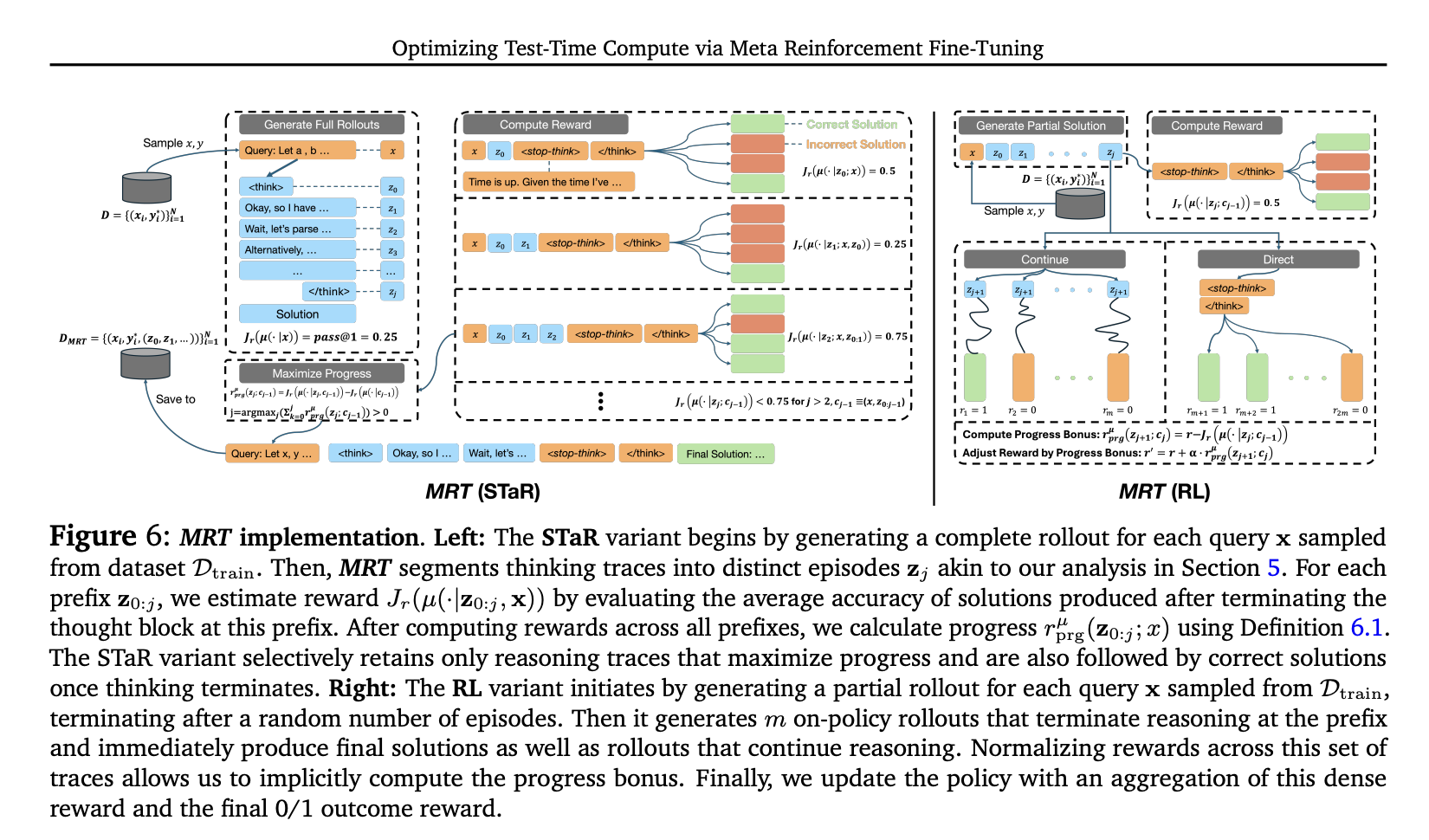
The optimization of test-time compute is framed as a meta reinforcement learning (meta RL) challenge. The objective is to maximize an LLM’s performance within a specified token budget by balancing exploration and exploitation. The proposed Meta Reinforcement Fine-Tuning (MRT) approach minimizes cumulative regret by rewarding progress across sequential episodes, allowing LLMs to make steady advancements regardless of training constraints.
Effectiveness and Results
The study evaluates MRT’s effectiveness in optimizing test-time computation, focusing on achieving high accuracy while maintaining efficiency. Findings demonstrate that MRT outperforms existing methods, enhancing both accuracy and token efficiency. It also shows improved robustness for out-of-distribution scenarios and delivers significant performance gains with weaker models.
Conclusion
This research reframes the optimization of test-time compute as a meta-reinforcement learning problem, introducing cumulative regret as a crucial metric. Current outcome-reward RL models often struggle with novel queries within a token budget due to their lack of granularity in guiding stepwise progress. MRT addresses this by incorporating a dense reward bonus that promotes incremental improvement, achieving 2-3 times better performance and 1.5 times greater token efficiency in mathematical reasoning compared to traditional outcome-reward RL.
Getting Started with AI
Explore how artificial intelligence can transform your business processes:
- Identify areas where AI can automate tasks and enhance customer interactions.
- Determine key performance indicators (KPIs) to measure the impact of your AI investments.
- Select tools that align with your needs and allow for customization.
- Start with a small project, gather data on its effectiveness, and gradually expand your AI initiatives.
Contact Us
If you need assistance in managing AI in your business, reach out to us at hello@itinai.ru. Connect with us on Telegram, X, and LinkedIn.

























