
Understanding LLM Inference Challenges
Large Language Model (LLM) inference requires a lot of memory and computing power. To solve this, we use model parallelism strategies that share workloads across multiple GPUs. This helps reduce memory issues and speeds up the inference process.
What is Tensor Parallelism?
Tensor Parallelism (TP) is a common method that divides weights and activations among GPUs, allowing them to work together on a single request. Unlike other methods, TP synchronizes operations across GPUs, which helps scale efficiently. However, this synchronization can slow down inference due to communication delays, sometimes causing up to 38% of total latency.
Improving Communication Efficiency
Previous research has tried to reduce these delays by overlapping computation with data transfer. Techniques like optimized GPU kernels and domain-specific languages have shown potential but are often complex to implement. As hardware evolves, these solutions may need constant updates. Other strategies have been explored, but communication latency remains a key challenge.
Introducing Ladder Residual
Researchers from USC, MIT, and Princeton developed Ladder Residual, a model adjustment that improves TP efficiency by separating computation from communication. This method reroutes connections, allowing for overlapping processes and reducing delays. When applied to a 70B-parameter Transformer, it achieved a 30% speedup across eight GPUs.
Benefits of Ladder Residual
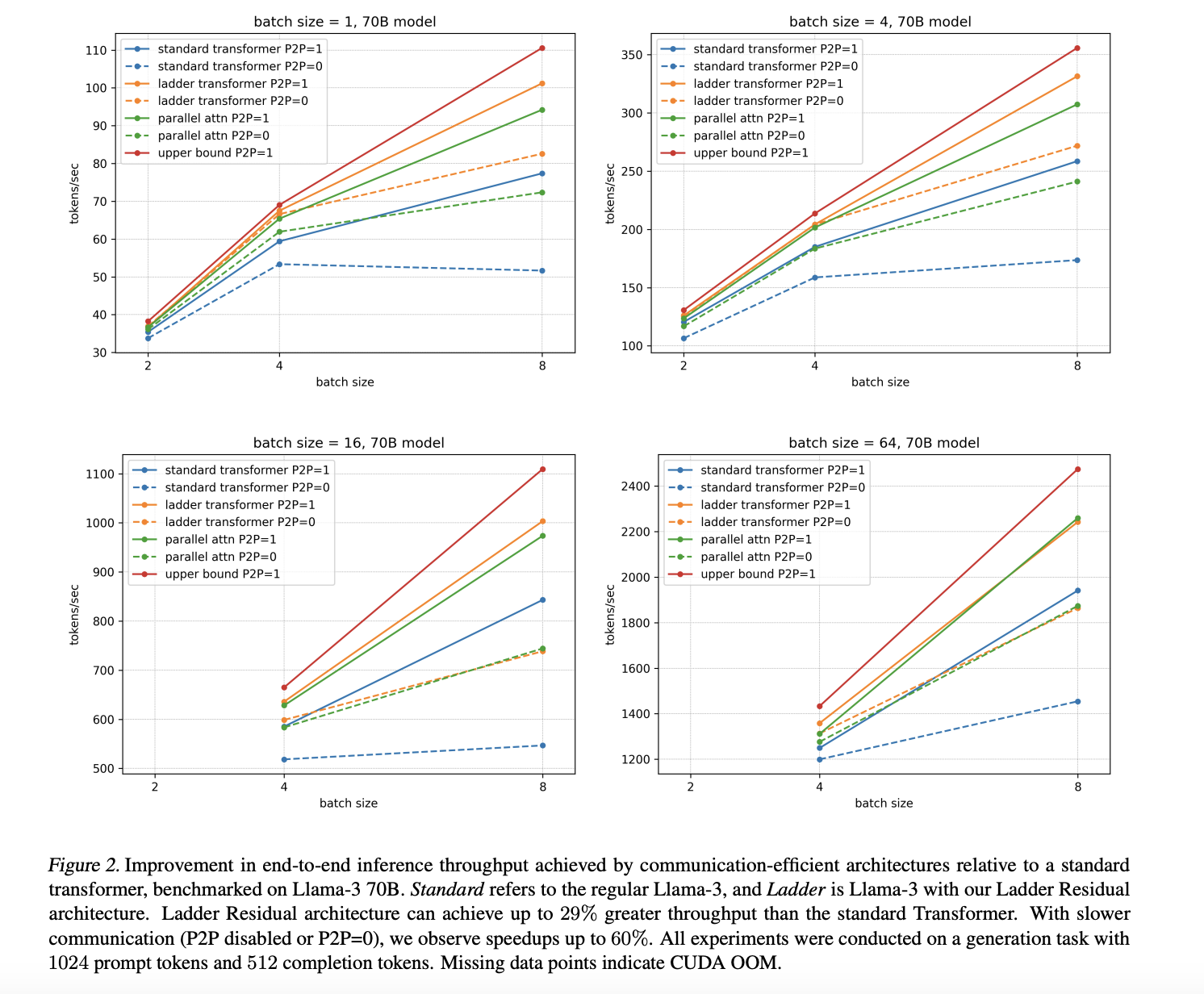
The Ladder Transformer, using Ladder Residual, enhances efficiency by allowing asynchronous operations. Testing on various model sizes, including Llama-3 70B, showed up to a 29% increase in inference speed, with gains reaching 60% in slower communication scenarios. This method allows for faster processing and lower latency without losing accuracy, even in large-scale setups.
Performance Evaluation
The study assessed Ladder Residual’s impact by training 1B and 3B Ladder Transformers and comparing them to standard models. Results indicated that Ladder Transformers perform similarly to standard models, with a slight drop at 3B. Applying Ladder Residual to Llama-3.1-8B showed an initial performance dip, recoverable through fine-tuning, leading to a 21% speedup in inference.
Conclusion
Ladder Residual is a promising architectural change that enhances model parallelism by improving communication and computation overlap. It boosts inference speed without sacrificing performance. The approach shows significant improvements, with over 55% speedup in some cases. This method reduces reliance on costly interconnects, paving the way for better model architectures and inference systems.
Get Involved
Check out the Paper for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Join our 75k+ ML SubReddit community!
Transform Your Business with AI
To stay competitive, leverage the insights from optimizing large model inference. Here’s how:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram or @itinaicom.
Discover how AI can transform your sales processes and customer engagement. Explore solutions at itinai.com.
























