
Optimizing Reasoning Performance in Language Models: Practical Business Solutions
Understanding Inference-Time Scaling Methods
Language models are powerful tools that can perform a variety of tasks, but they often struggle with complex reasoning. This difficulty usually requires more computational resources and specialized techniques. To address this, inference-time compute (ITC) scaling methods have been developed, which allocate additional computational resources to improve model performance during inference.
The evolution of language model reasoning has focused on two key areas: enhancing reasoning capabilities during inference and developing specialized models. However, these enhancements can lead to significant computational costs, prompting a need for a balance between resource use and reasoning effectiveness.
Promising Alternatives to Pretraining
Inference-time scaling presents a cost-effective alternative to expensive model pretraining. Techniques such as generation ensembling, sampling, ranking, and fusion have shown to improve performance beyond that of individual models. Notable examples include:
- Mixture-of-Agents
- LLM Blender
- DSPy orchestration frameworks
Additional methods like Confidence-Informed Self-Consistency (CISC) and DivSampling enhance efficiency by reducing the number of samples needed and increasing answer diversity, respectively.
Research Insights and Case Studies
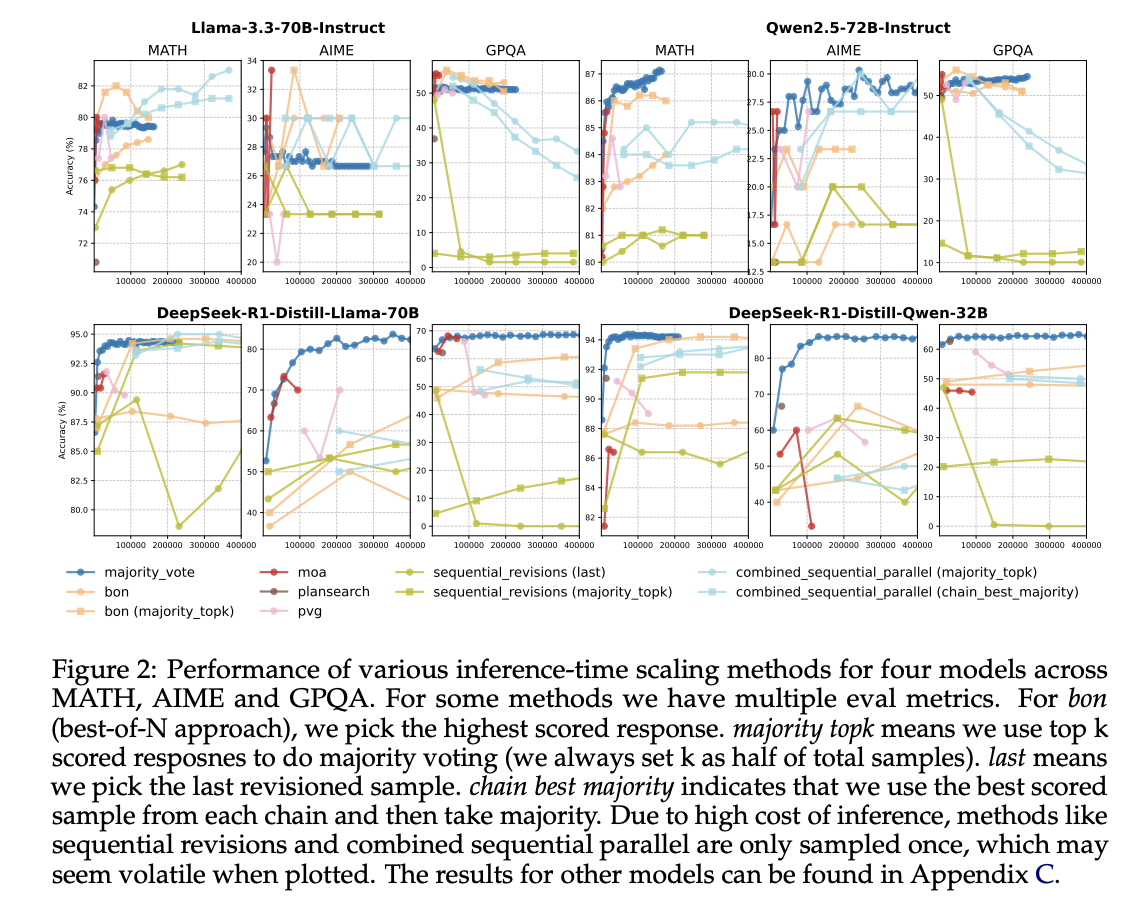
A collaborative study from leading universities, including Duke and Stanford, analyzed the effectiveness of various ITC methods in reasoning tasks. They constructed the Pareto frontier of quality and efficiency, revealing that non-reasoning models, even with high inference budgets, consistently underperform compared to reasoning models. A striking finding was that majority voting outperformed more complex ITC strategies like best-of-N and sequential revisions.
For instance, R1-Distilled versions of models like Llama-3.3-70B significantly outperformed their original counterparts, illustrating the advantage of investing in specialized reasoning models over general ones. This suggests that for efficient computing, training dedicated reasoning models is a more effective long-term strategy.
Key Observations on Response Quality
The study revealed that non-reasoning models often lack a correlation between response length and accuracy, while reasoning models showed that shorter responses tend to be more accurate. This indicates that response characteristics can serve as predictors of model performance. For example, analysis of the MATH dataset confirmed that reasoning models generated more accurate responses for challenging problems with shorter answers.
Conclusion: Strategic Recommendations
In summary, the analysis of verifier-free inference-time scaling methods has highlighted their efficiency for reasoning tasks. Despite the use of advanced scaling techniques, non-reasoning models consistently fall short compared to specialized reasoning models. Simpler strategies like majority voting prove to be more effective than complex methods.
As businesses consider integrating AI, the following strategies are recommended:
- Identify areas for automation and where AI can add real value.
- Establish key performance indicators (KPIs) to measure the impact of AI investments.
- Select customizable tools that align with your business objectives.
- Start small, gather data on effectiveness, and gradually expand AI applications.
For further guidance on managing AI in your business, please reach out to us at hello@itinai.ru. Follow us on Telegram, X, and LinkedIn.























