
The Challenge of Factual Accuracy in AI
The emergence of large language models has brought challenges, especially regarding the accuracy of their responses. These models sometimes produce factually incorrect information, a problem known as “hallucination.” This occurs when they confidently present false or unverifiable data. As reliance on AI grows, ensuring factual accuracy is essential, yet evaluating it can be complex, especially with lengthy responses that contain multiple claims.
Introducing SimpleQA
OpenAI has launched SimpleQA, an open-source benchmark designed to assess the factuality of language model responses. SimpleQA focuses on short, straightforward questions with clear answers, making it easier to evaluate accuracy. Unlike other benchmarks that can become outdated, SimpleQA remains relevant and challenging for current AI models.
Key Features of SimpleQA
- Adversarial Question Design: Questions are created to challenge even the most advanced models like GPT-4.
- Wide Range of Topics: SimpleQA covers various domains—history, science, technology, art, and entertainment—to ensure a comprehensive evaluation.
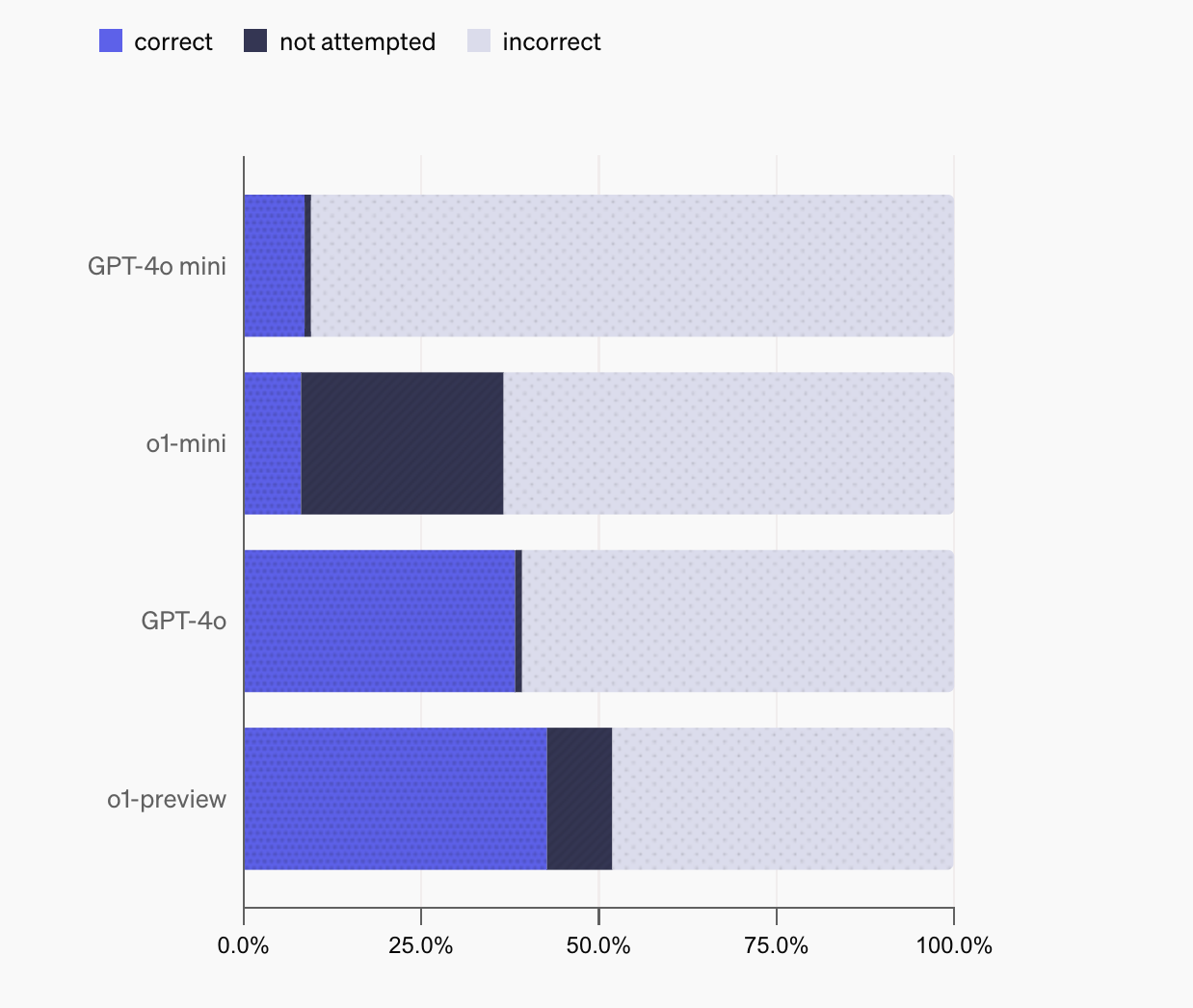
- Clear Grading System: Each question has a verified reference answer, and responses are classified as “correct,” “incorrect,” or “not attempted.”
- Evergreen Relevance: Questions are designed to remain relevant over time, eliminating the impact of changing information.
The Importance of SimpleQA
SimpleQA is essential for evaluating the factual capabilities of language models. While other benchmarks may be outdated, SimpleQA consistently challenges models like GPT-4 and Claude-3.5, revealing areas where they struggle. This benchmark offers valuable insights into the reliability of language models, particularly their ability to recognize when they have enough information to respond accurately.
Grading Metrics
SimpleQA provides detailed metrics on model performance, including overall accuracy and precision. The benchmark shows that larger models often overstate their confidence, with many incorrect attempts. While larger models are better at knowing when they have the correct answer, there is still significant room for improvement.
A Step Towards Reliable AI
SimpleQA represents a crucial advancement in ensuring the reliability of AI-generated information. By focusing on clear, factual questions, it serves as a practical tool for evaluating language models. This benchmark encourages the development of models that generate truthful content consistently, contributing to the creation of trustworthy AI systems.
Get Involved!
Explore the research details and the GitHub page for SimpleQA. Join our community on Twitter, Telegram, and LinkedIn for the latest updates. If you appreciate our work, subscribe to our newsletter. Also, connect with over 55k members in our ML SubReddit.
Discover AI Solutions for Your Business
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose customizable tools that meet your needs.
- Implement Gradually: Start with a pilot project, gather data, and scale wisely.
For AI KPI management advice, reach out to us at hello@itinai.com. Stay updated on leveraging AI through our Telegram channel or Twitter.
Transform Your Sales and Customer Engagement
Discover innovative solutions to redefine your approach at itinai.com.
























