
Enhancing Real-Time Audio Interactions with OpenAI’s Advanced Audio Models
Introduction
The rapid growth of voice interactions in digital platforms has raised user expectations for seamless and natural audio experiences. Traditional speech synthesis and transcription technologies often struggle with latency and unnatural sound, making them less effective for user-centric applications. To address these challenges, OpenAI has introduced a suite of advanced audio models designed to revolutionize real-time audio interactions.
Overview of OpenAI’s Audio Models
OpenAI has launched three innovative audio models through its API, significantly enhancing developers’ capabilities in real-time audio processing. These models include:
- gpt-4o-mini-tts – A text-to-speech model that generates realistic speech from text inputs.
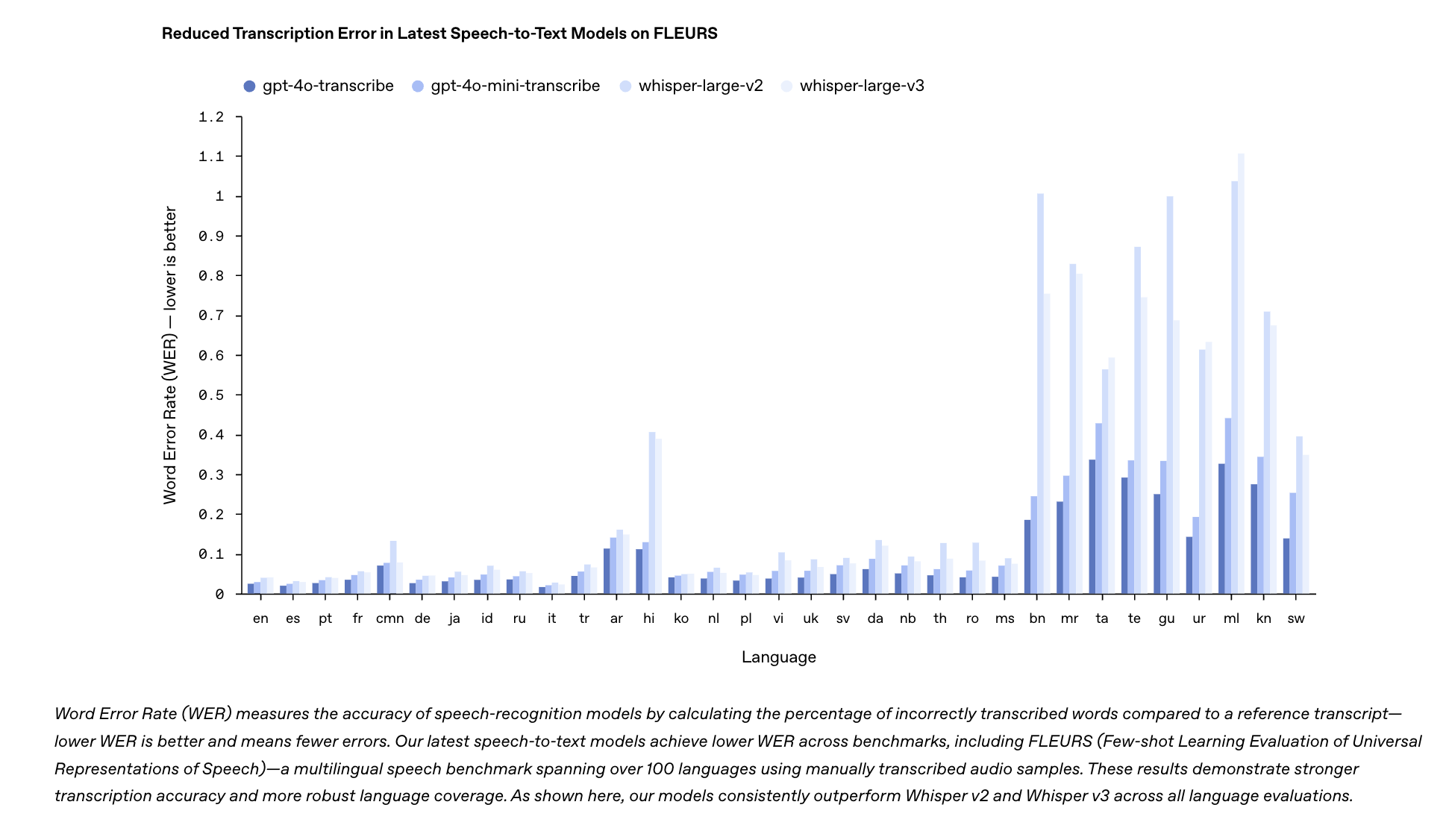
- gpt-4o-transcribe – A high-accuracy speech-to-text model optimized for complex audio environments.
- gpt-4o-mini-transcribe – A lightweight speech-to-text model designed for speed and low-latency transcription.
These models reflect OpenAI’s commitment to improving user experiences across digital interfaces, focusing on both incremental improvements and transformative changes in audio interactions.
Key Features and Benefits
gpt-4o-mini-tts
This model allows developers to create highly natural-sounding speech from text. It offers significantly lower latency and enhanced clarity compared to previous technologies, making it ideal for applications such as virtual assistants, audiobooks, and real-time translation devices.
gpt-4o-transcribe and gpt-4o-mini-transcribe
These transcription models are tailored for different use cases:
- gpt-4o-transcribe – Best for high-accuracy transcription in noisy environments, ensuring quality even under challenging acoustic conditions.
- gpt-4o-mini-transcribe – Optimized for speed, making it suitable for applications where low latency is critical, such as voice-enabled IoT devices.
Case Studies and Historical Context
The introduction of these audio models builds on the success of OpenAI’s previous innovations, such as GPT-4 and Whisper. Whisper set new standards for transcription accuracy, while GPT-4 enhanced conversational AI capabilities. The new audio models extend these advancements into the audio domain, providing developers with powerful tools for creating engaging audio experiences.
Practical Business Solutions
To leverage these advanced audio models effectively, businesses should consider the following steps:
- Identify Automation Opportunities: Look for processes in customer interactions where AI can add significant value.
- Define Key Performance Indicators (KPIs): Establish metrics to evaluate the impact of AI investments on business performance.
- Select Appropriate Tools: Choose tools that align with your business needs and allow for customization.
- Start Small: Initiate a pilot project, gather data on its effectiveness, and gradually expand AI usage.
Conclusion
OpenAI’s advanced audio models, including gpt-4o-mini-tts, gpt-4o-transcribe, and gpt-4o-mini-transcribe, are set to enhance user interactions and overall functionality in various applications. With improved real-time audio processing, these tools position businesses to stay ahead in a competitive landscape, ensuring responsiveness and clarity in audio communications.



























