
Understanding the Challenges in Software Engineering
Software engineering faces new challenges that traditional benchmarks can’t address. Freelance software engineers deal with complex tasks that go beyond simple coding. They manage entire codebases, integrate different systems, and meet various client needs. Standard evaluation methods often overlook important factors like overall performance and the financial impact of solutions. This highlights the need for more realistic assessment methods.
Introducing SWE-Lancer
SWE-Lancer is a new benchmark created by OpenAI to evaluate how well models perform in real-world freelance software engineering tasks. It is based on over 1,400 tasks from Upwork and the Expensify repository, with a total payout of $1 million USD. Tasks range from small bug fixes to significant feature implementations.
Key Features of SWE-Lancer
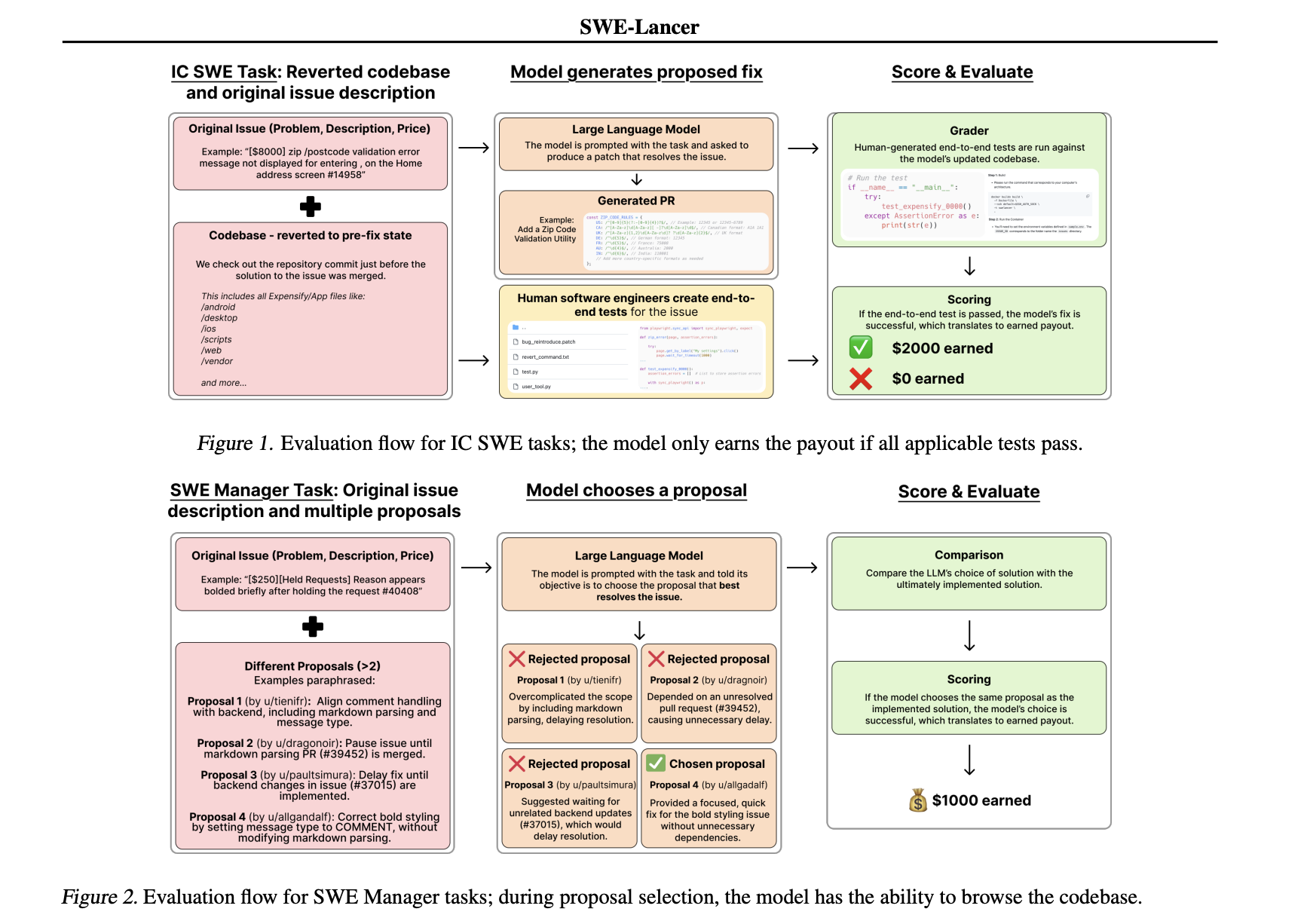
- Evaluates both code patches and decision-making skills.
- Uses end-to-end tests, simulating the entire user workflow.
- Ensures consistent testing conditions with a unified Docker image.
Realistic Task Design
SWE-Lancer’s tasks reflect the realities of freelance work, requiring changes across multiple files and API integrations. Models must also review and choose the best proposals, showcasing both technical and managerial skills. A user tool simulates real interactions, promoting iterative debugging and adjustments.
Insights from SWE-Lancer Results
Results from SWE-Lancer reveal the capabilities of language models in software engineering. For individual tasks, models like GPT-4o and Claude 3.5 Sonnet had pass rates of 8.0% and 26.2%, respectively. In managerial tasks, the best model achieved a pass rate of 44.9%. These findings indicate that while advanced models show promise, there is still significant room for improvement.
Conclusion
SWE-Lancer offers a realistic way to evaluate AI in software engineering, linking model performance to real monetary value and emphasizing full-stack challenges. It encourages a shift from synthetic metrics to assessments that reflect the true economic and technical realities of freelance work. This benchmark is a valuable tool for researchers and practitioners, providing insights into current limitations and opportunities for improvement.
Explore More
Check out the Paper for more details. Follow us on Twitter and join our 75k+ ML SubReddit for updates.
Transform Your Business with AI
Stay competitive by leveraging SWE-Lancer to enhance your operations:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI projects have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot program, gather data, and expand wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram at t.me/itinainews or on Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.























