
Introducing Open-Qwen2VL: A Groundbreaking Multimodal Large Language Model
Understanding the Challenge in Multimodal Models
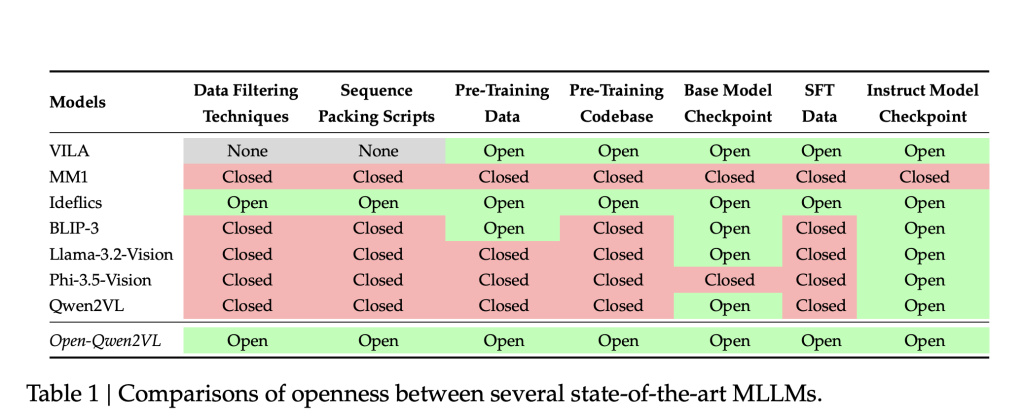
Multimodal Large Language Models (MLLMs) are becoming essential in bridging visual and textual data, enhancing tasks like image captioning, visual question answering, and document interpretation. However, the lack of transparency in replicating and improving upon these models can be a major hurdle. Many leading MLLMs do not share critical elements such as their training code, data collection methods, or pretraining datasets. This opacity can significantly obstruct reproducibility and slow innovation in research, particularly in academic settings with limited computational resources.
Open-Qwen2VL: A Solution to Accessibility and Efficiency
The launch of Open-Qwen2VL, developed by researchers from UC Santa Barbara, ByteDance, and NVIDIA, presents a breakthrough in MLLM accessibility. With 2 billion parameters, this model has been pre-trained on 29 million image-text pairs, utilizing about 220 A100-40G GPU hours. Open-Qwen2VL directly addresses issues of transparency and resource constraints in MLLM research by providing a complete suite of open-source resources.
- Training codebase
- Data filtering scripts
- WebDataset-formatted pretraining data
- Model checkpoints for both base and instruction-tuned versions
This comprehensive release aims to foster transparent experimentation and innovation in the multimodal learning sphere.
Operational Efficiency and Performance Metrics
The architecture of Open-Qwen2VL is built on the Qwen2.5-1.5B-Instruct LLM backbone, coupled with a SigLIP-SO-400M vision encoder. A unique Adaptive Average-Pooling Visual Projector reduces visual tokens from 729 to 144 during pretraining, enhancing computational efficiency. Through a strategy that increases token count back during the fine-tuning stage, the model maintains robust image understanding capabilities while optimizing resource usage.
Notably, Open-Qwen2VL uses only 0.36% of the token count from previous models yet remains competitive, achieving notable scores across various benchmarks:
- MMBench: 80.9
- SEEDBench: 72.5
- MMStar: 49.7
- MathVista: 53.1
Research indicates that utilizing a smaller subset (5 million samples) of high-quality image-text pairs can lead to significant performance enhancements, emphasizing the importance of data quality.
Few-Shot Learning Capabilities
Open-Qwen2VL also excels in few-shot multimodal in-context learning. Evaluations on datasets such as GQA and TextVQA reveal accuracy improvements of 3% to 12% as the number of training examples increases from 0-shot to 8-shot scenarios. Performance gains plateau around 8 million examples from the MAmmoTH-VL-10M dataset, providing insight into the scaling of instruction tuning.
Conclusion: Moving Forward in Multimodal AI Research
Open-Qwen2VL offers a reproducible and resource-efficient framework for developing multimodal large language models. By overcoming previous limitations in transparency and computational demands, it opens avenues for increased participation in MLLM research. Its design features, such as efficient visual token processing and data curation, pave the way for academic institutions to contribute meaningfully to the field. This model not only establishes a replicable baseline but also serves as a catalyst for future advancements in scalable and high-performance MLLMs.

























