
Understanding O1-Pruner: Enhancing Language Model Efficiency
Key Features of Large Language Models
Large language models (LLMs) have impressive reasoning abilities. Models like OpenAI’s O1 break down complex problems into simpler steps, refining solutions through a process called “long-thought reasoning.” However, this can lead to longer output sequences, which increases computing time and energy consumption. These challenges hinder the real-world application of LLMs.
Introducing O1-Pruner
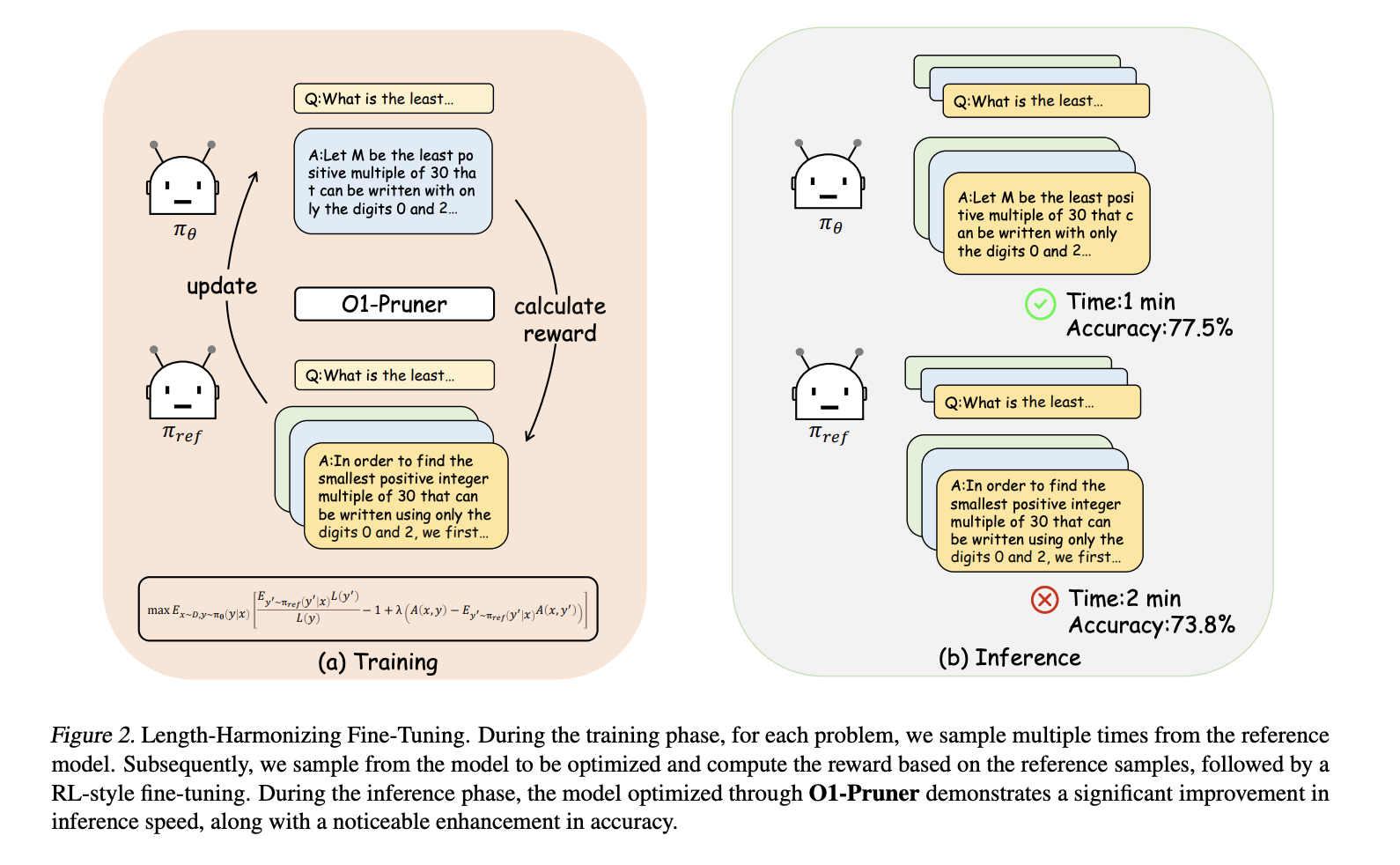
Researchers from several universities have developed a solution called Length-Harmonizing Fine-Tuning (O1-Pruner). This technique aims to make reasoning models more efficient while maintaining accuracy. O1-Pruner focuses on optimizing how tokens are used, reducing the bottleneck in current models. It employs reinforcement learning to generate shorter reasoning paths without losing precision.
How O1-Pruner Works
The O1-Pruner process includes:
– **Reference Model Sampling:** Evaluating reasoning quality and length against a benchmark.
– **Reward Function Design:**
– **Length Reward:** Encourages shorter solutions.
– **Accuracy Reward:** Ensures correctness is maintained.
– **Reinforcement Learning Framework:** Uses Proximal Policy Optimization (PPO) for efficient training.
Benefits of O1-Pruner
The advantages of using O1-Pruner are significant:
– **Improved Efficiency:** Minimizes unnecessary computations for quicker outputs.
– **Accuracy Preservation:** Maintains or even increases accuracy in shorter solutions.
– **Task Adaptability:** Adjusts reasoning depth based on task complexity.
Results from O1-Pruner
Testing on various mathematical reasoning benchmarks shows promising results:
– The Marco-o1-7B model reduced solution length by 40.5% while improving accuracy to 76.8%.
– The QwQ-32B-Preview model achieved a 34.7% reduction in solution length with a slight accuracy increase to 89.3%.
– Inference times also improved, with Marco-o1-7B reducing time from 2 minutes to just over 1 minute, and QwQ-32B-Preview from 6 minutes to about 4 minutes.
These outcomes demonstrate that O1-Pruner effectively balances efficiency and accuracy, outperforming traditional methods.
Conclusion
O1-Pruner shows that LLMs can achieve efficient reasoning without sacrificing accuracy. By aligning reasoning length with the complexity of problems, it addresses the computational inefficiencies of long-thought reasoning. This advancement paves the way for better performance in various real-world applications.
Get Involved
Explore the complete research paper and GitHub page. Follow us on Twitter and join our Telegram Channel and LinkedIn Group. Join our growing ML community on Reddit!
Leverage AI for Your Business
Transform your organization using O1-Pruner. Here’s how:
– **Identify Automation Opportunities:** Find key customer interactions that can benefit from AI.
– **Define KPIs:** Ensure measurable impacts from your AI initiatives.
– **Select an AI Solution:** Choose tools that fit your needs and allow for customization.
– **Implement Gradually:** Start small, gather insights, and expand AI usage wisely.
For AI KPI management tips, reach out to hello@itinai.com. For ongoing insights into AI, follow us on our Telegram and Twitter channels. Discover how AI can enhance your sales and customer engagement at itinai.com.

























