
Post-Training for Large Language Models (LLMs)
Understanding Post-Training: Post-training enhances LLMs by fine-tuning their performance beyond initial training. This involves techniques like supervised fine-tuning (SFT) and reinforcement learning to meet human needs and specific tasks.
The Role of Synthetic Data
Synthetic data is vital for improving LLMs, helping researchers evaluate and refine post-training methods. However, research is still new, with challenges related to data availability and scalability, making it hard to analyze different strategies effectively.
Challenges in the Field
Currently, the lack of large, publicly available synthetic datasets hampers progress. Researchers need access to diverse conversational datasets for meaningful studies. The absence of standardized datasets also affects evaluation consistency, while high costs for data generation limit opportunities for many academic institutions.
Current Approaches
Researchers are combining model-generated responses with benchmark datasets. While some datasets like WildChat-1M offer useful insights, they still have limitations in size and diversity. Techniques to assess data quality exist, but access to a comprehensive dataset for large-scale experimentation is still missing.
Introducing WILDCHAT-50M
Researchers from New York University have launched WILDCHAT-50M, a huge dataset for LLM post-training. This dataset builds on WildChat and includes responses from more than 50 models, making it the largest diverse public dataset of chat transcripts.
Key Features of WILDCHAT-50M
- Scale: About 125 million chat transcripts from over a million multi-turn conversations.
- Efficiency: Developed using 12×8 H100 GPUs to optimize performance.
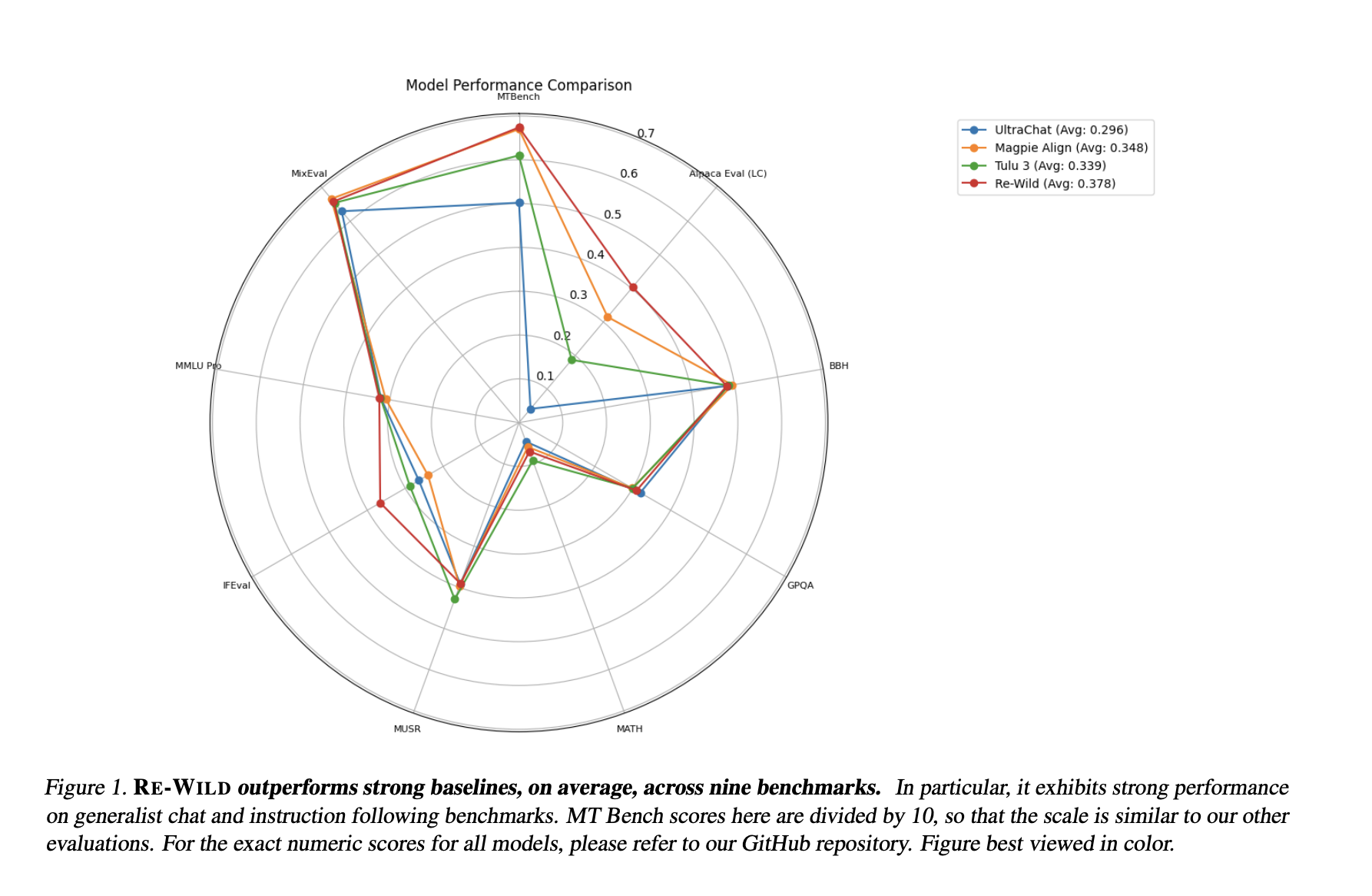
- Impact: Supports the RE-WILD approach to improve LLM training efficiency.
Validation and Performance
WILDCHAT-50M has been validated through strict benchmarks, showing significant improvements over previous models with less data. It enhances response coherence, alignment, and processing speed, leading to better instruction-following capabilities.
Importance of WILDCHAT-50M
This dataset is crucial for advancing LLM post-training and offers insights into effective data generation models. It’s expected to foster further academic and industry research, enhancing the adaptability and efficiency of language models.
Get Involved
Explore the Paper, Dataset on Hugging Face, and GitHub Page. For updates, follow us on Twitter, join our Telegram Channel, and connect on our LinkedIn Group. Join our thriving ML community on SubReddit.
Enhance Your Business with AI
Unlock AI Potential: Leverage WILDCHAT-50M to transform your company.
- Identify Automation Opportunities: Find areas in customer interactions suitable for AI.
- Define KPIs: Ensure AI initiatives have measurable business impacts.
- Select the Right AI Solution: Choose tools that fit your requirements and allow customization.
- Implement Gradually: Start small, gather data, and expand usage wisely.
For expert advice on AI KPI management, contact us at hello@itinai.com. Stay informed on AI insights via our Telegram Channel and Twitter @itinaicom.
Discover how AI can revolutionize your sales processes and customer engagement on our website itinai.com.

























