
NVIDIA AI Researchers Unveil FFN Fusion: A Breakthrough in Large Language Model Efficiency
Introduction to Large Language Models
Large language models (LLMs) are increasingly essential in various sectors, powering applications such as natural language generation, scientific research, and conversational agents. These models rely on transformer architecture, which processes input through alternating layers of attention mechanisms and feed-forward networks (FFNs). However, as these models grow in size and complexity, the computational demands for inference increase significantly, leading to efficiency challenges.
The Challenge of Sequential Computation
The sequential nature of transformers poses a significant bottleneck. Each layer’s output must be processed in a strict order, which becomes problematic as model sizes expand. This sequential computation leads to increased costs and reduced efficiency, particularly in applications requiring rapid multi-token generation, such as real-time AI assistants. Addressing this challenge is crucial for enhancing the scalability and accessibility of LLMs.
Current Techniques and Their Limitations
Several methods have been developed to improve efficiency:
- Quantization: Reduces numerical precision to save memory and computation but risks accuracy loss.
- Pruning: Eliminates redundant parameters to simplify models, though it can affect accuracy.
- Mixture-of-Experts (MoE): Activates only a subset of parameters for specific tasks, but may underperform at intermediate batch sizes.
While these strategies have their merits, they often come with trade-offs that limit their effectiveness across diverse applications.
Introducing FFN Fusion
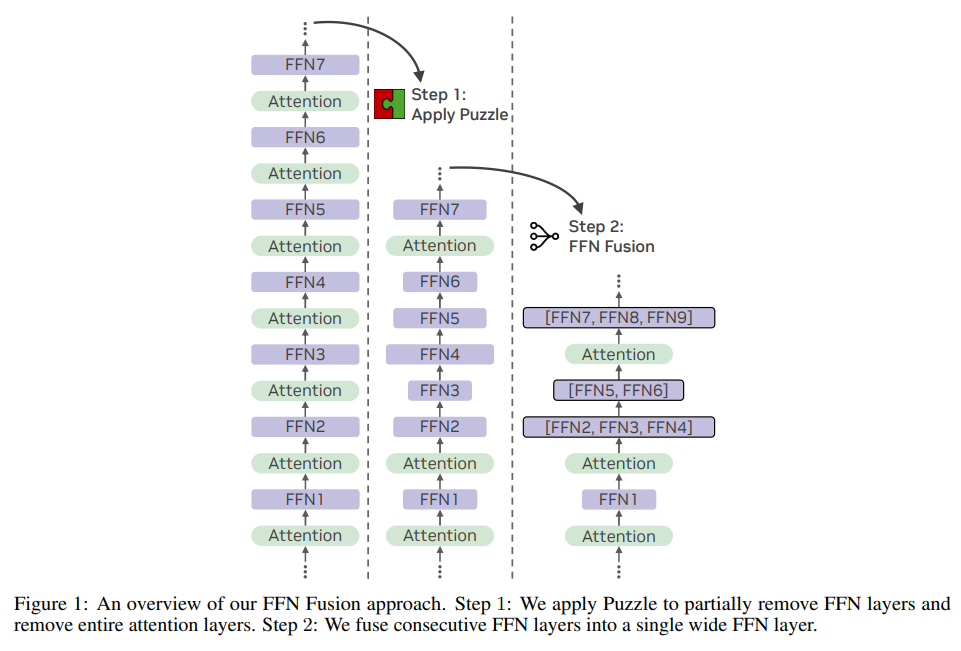
NVIDIA researchers have developed a novel optimization technique called FFN Fusion, which addresses the sequential bottleneck in transformers. This technique allows for the parallel execution of FFN sequences that exhibit minimal interdependency. By analyzing models like Llama-3.1-405B-Instruct, researchers created a new model, Ultra-253B-Base, which is both efficient and high-performing.
How FFN Fusion Works
FFN Fusion combines multiple consecutive FFN layers into a single, wider FFN. This process is based on mathematical principles that allow for parallel computation without sacrificing performance. For example, if three FFNs are traditionally stacked, their fusion enables simultaneous processing, significantly enhancing efficiency.
Results and Performance Metrics
The application of FFN Fusion to the Llama-405B model resulted in the Ultra-253B-Base, which achieved:
- 1.71x improvement in inference latency
- 35x reduction in per-token computational cost
- Benchmark scores: 85.17% (MMLU), 72.25% (MMLU-Pro), 86.58% (HumanEval), 84.92% (Arena Hard), 9.19 (MT-Bench)
- 50% reduction in memory usage due to kv-cache optimization
These results demonstrate that Ultra-253B-Base not only maintains competitive performance but also operates with significantly reduced resource requirements.
Key Takeaways
- FFN Fusion effectively reduces sequential computation by parallelizing low-dependency FFN layers.
- The technique is validated across various model sizes, proving its versatility.
- Further research is needed to explore full transformer block parallelization due to stronger interdependencies.
Conclusion
The introduction of FFN Fusion marks a significant advancement in the efficiency of large language models. By rethinking architectural design, researchers have unlocked new levels of performance while reducing computational costs. This approach not only enhances the scalability of LLMs but also paves the way for more efficient AI applications across industries.



























