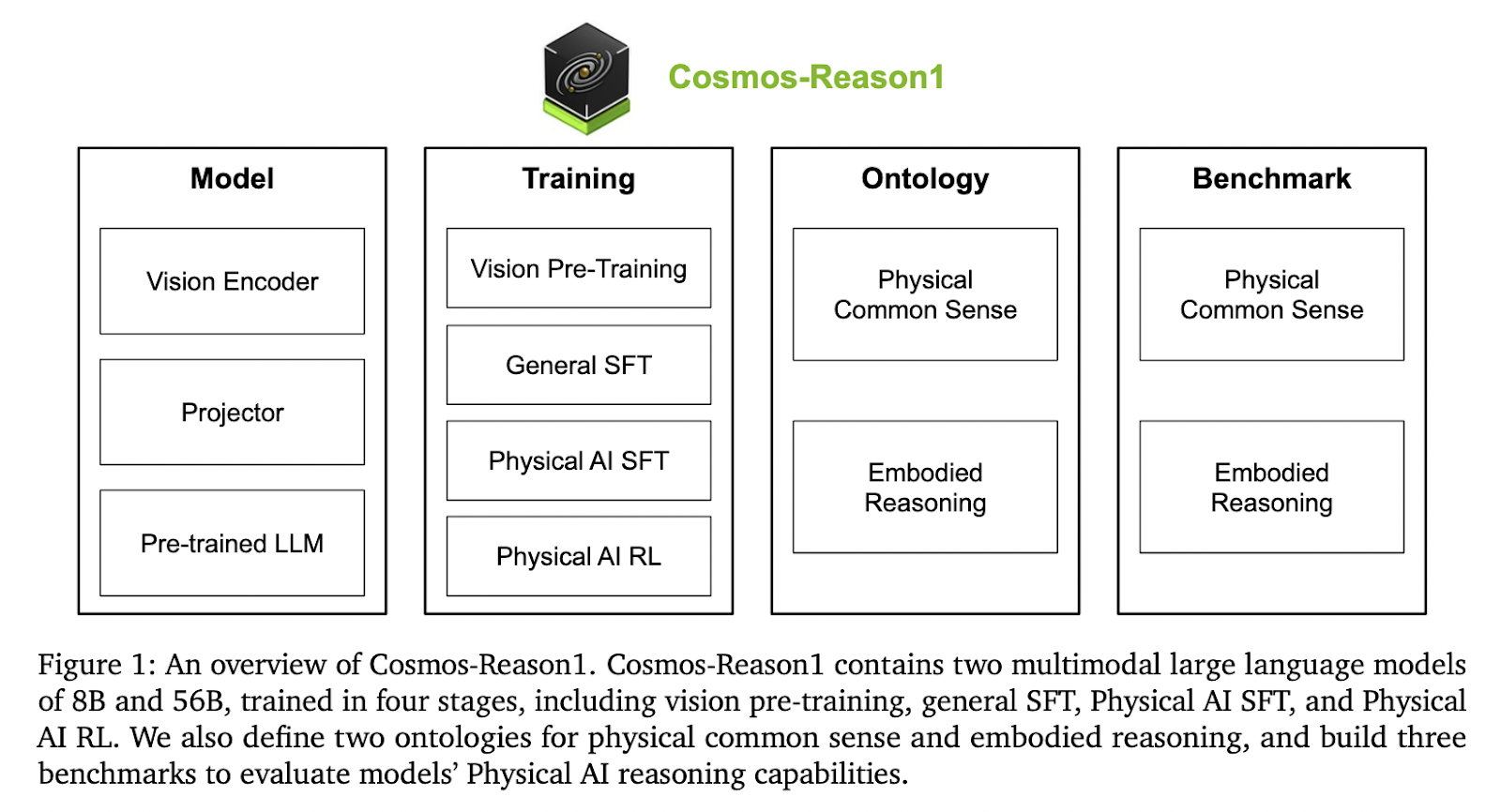
Introduction to Cosmos-Reason1: A Breakthrough in Physical AI
The recent AI research from NVIDIA introduces Cosmos-Reason1, a multimodal model designed to enhance artificial intelligence’s ability to reason in physical environments. This advancement is crucial for applications such as robotics, self-driving vehicles, and assistive technologies, where understanding spatial dynamics and cause-and-effect relationships is essential for making intelligent decisions.
The Need for Physical AI
Traditional AI systems often struggle with interpreting complex visual scenarios and making decisions based on their surroundings. They lack the ability to integrate visual information with contextual reasoning, which is vital for tasks that require understanding physical interactions. For example, in high-stakes environments, an AI’s inability to verify its reasoning can lead to unreliable outcomes.
Challenges in Current AI Models
- Limited Reasoning Capabilities: Existing models like LLaVA and GPT-4o excel in processing text and images but fall short in physical reasoning tasks.
- Benchmark Limitations: Current benchmarks do not adequately assess a model’s ability to handle physical events or actions, leading to gaps in performance evaluation.
- Dependency on Textual Cues: Many AI systems rely heavily on textual information rather than visual evidence, resulting in inconsistent conclusions.
Introducing Cosmos-Reason1
NVIDIA’s Cosmos-Reason1 addresses these challenges with a structured approach that includes:
- Model Architecture: A hybrid Mamba-MLP-Transformer architecture that combines vision and language components.
- Specialized Training: The model underwent multiple training phases, including pretraining on general data and fine-tuning with datasets focused on physical interactions.
- Comprehensive Evaluation: A suite of benchmarks was developed to rigorously test capabilities in action prediction, task verification, and physical feasibility.
Performance Insights
The evaluation of Cosmos-Reason1 revealed significant improvements over previous models:
- Physical Common Sense: The 56 billion parameter model achieved 60.2% accuracy, surpassing OpenAI’s o1 model.
- Embodied Reasoning: The same model scored 63.7% on embodied reasoning tasks, indicating a substantial enhancement from the baseline.
- Intuitive Physics Tasks: The 8 billion parameter model improved to 68.7%, showcasing its ability to reason about object permanence and spatial puzzles.
Case Study: Practical Applications
Businesses can leverage Cosmos-Reason1 in various ways:
- Robotics: Enhance robotic systems to navigate complex environments safely and efficiently.
- Self-Driving Vehicles: Improve decision-making processes in dynamic traffic situations.
- Assistive Technologies: Develop smarter devices that better understand user interactions and needs.
Conclusion
In summary, NVIDIA’s Cosmos-Reason1 represents a significant leap forward in the development of AI systems capable of reasoning about physical interactions. By combining structured fine-tuning with advanced reinforcement learning, this model addresses critical gaps in embodied reasoning. As businesses explore the potential of AI, adopting such innovative technologies can lead to more intelligent and effective solutions in real-world applications.



