
NVIDIA AI Releases Describe Anything 3B: A Practical Overview
Introduction
NVIDIA has introduced Describe Anything 3B (DAM-3B), a groundbreaking multimodal AI model designed specifically for fine-grained image and video captioning. This model addresses significant challenges in creating detailed descriptions for specific regions within visual content, a task that has historically posed difficulties for vision-language models.
Challenges in Localized Captioning
Localized captioning in vision-language models faces several key challenges:
- Loss of Detail: General-purpose models often fail to capture intricate details when extracting visual features.
- Insufficient Data: There is a lack of annotated datasets focused on regional descriptions, which hampers model training.
- Evaluation Limitations: Existing benchmarks may penalize models for accurate outputs due to incomplete reference captions.
Introducing Describe Anything 3B
DAM-3B is designed to overcome these challenges by providing localized descriptions with high accuracy. The model accepts various input formats, such as points, bounding boxes, scribbles, or masks, allowing it to generate contextually relevant text for both static images and dynamic videos. The model is publicly available through Hugging Face, making it accessible for various applications.
Core Architectural Innovations
The architecture of DAM-3B features two main innovations:
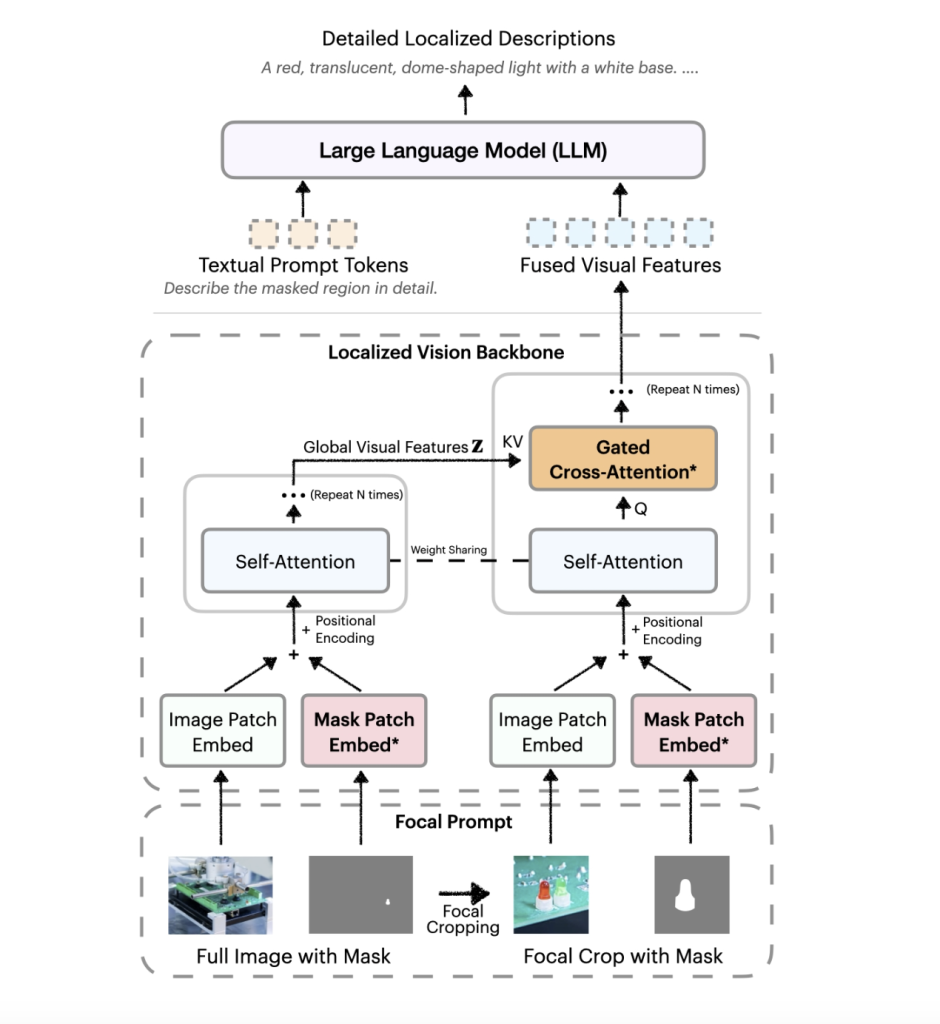
- Focal Prompt: This component combines a full image with a high-resolution crop of the target region, preserving both regional detail and broader context.
- Localized Vision Backbone: This backbone utilizes gated cross-attention to effectively merge global and focal features, ensuring computational efficiency without increasing token length.
Extending to Video: DAM-3B-Video
The DAM-3B-Video variant adapts the model for temporal sequences, allowing it to generate region-specific descriptions for videos while managing challenges such as occlusion and motion.
Data Strategy and Evaluation
To address data scarcity, NVIDIA implemented the DLC-SDP pipeline, a semi-supervised data generation strategy. This two-stage approach curates a training dataset of 1.5 million localized examples, enhancing the quality of region descriptions through self-training methods.
Evaluation Metrics
NVIDIA has developed the DLC-Bench to evaluate description quality based on attribute-level correctness, rather than strict comparisons with reference captions. DAM-3B has outperformed other models, achieving an average accuracy of 67.3% across seven benchmarks, including keyword-level and multi-sentence localized captioning tasks.
Case Studies and Applications
The capabilities of DAM-3B have broad implications across various sectors:
- Accessibility Tools: Enhancing the experience for visually impaired users by providing detailed descriptions of visual content.
- Robotics: Improving object recognition and interaction in robotic systems.
- Video Content Analysis: Enabling more effective content categorization and search functionalities.
Conclusion
In summary, Describe Anything 3B represents a significant advancement in localized captioning for images and videos. By integrating a context-aware architecture with a robust data generation pipeline, NVIDIA has set a new standard for multimodal AI systems. This model not only enhances the quality of visual content descriptions but also opens avenues for innovation across various industries.























