
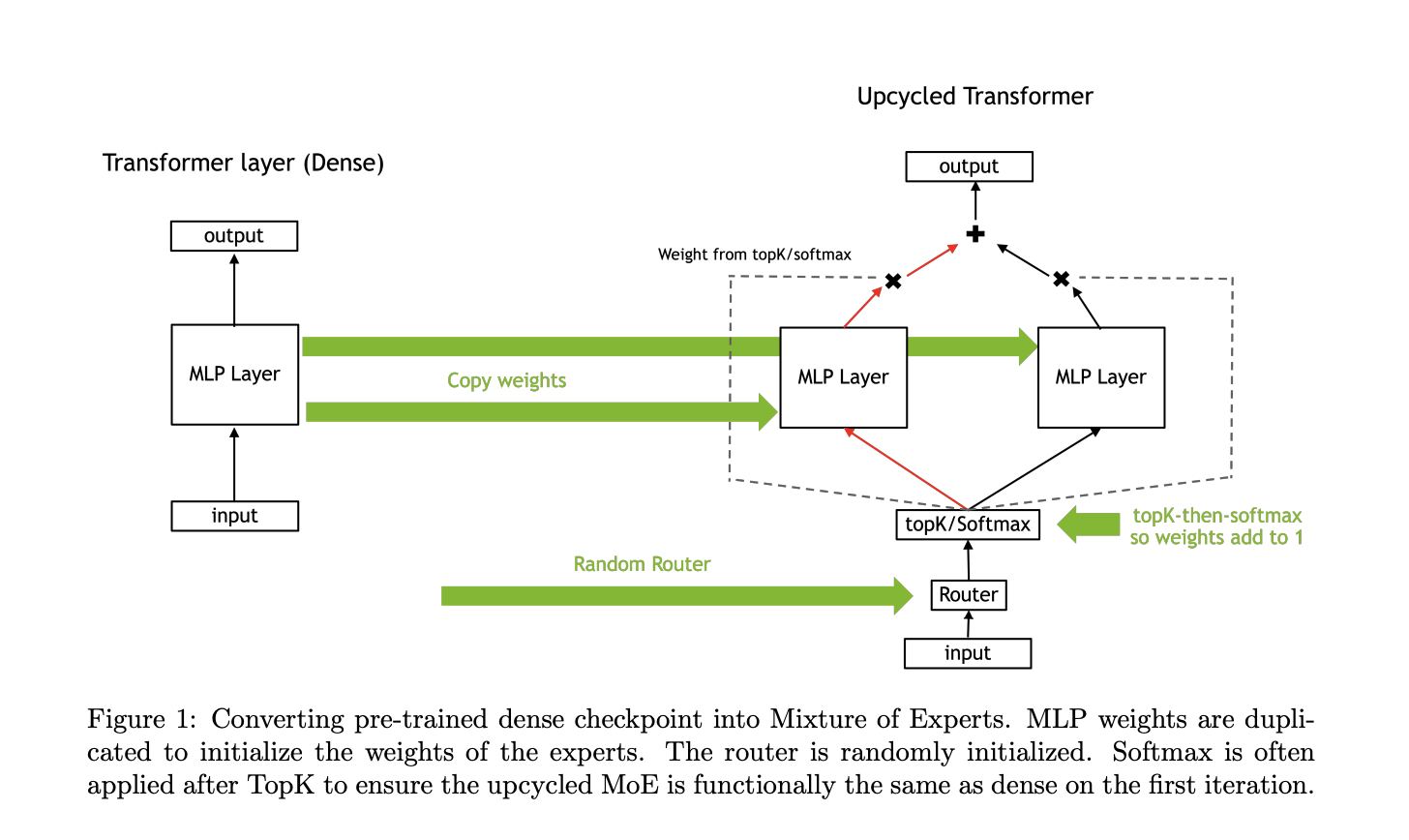
Understanding Mixture of Experts (MoE) Models
Mixture of Experts (MoE) models are essential for advancing AI, especially in natural language processing. Unlike traditional models, MoE architectures activate specific expert networks for each input, enhancing capacity without needing more computational resources. This approach allows researchers to improve the efficiency and accuracy of large language models (LLMs) without the high costs of training new models from scratch.
Benefits of Upcycling Dense Models
Dense models often hit a performance plateau after extensive training. To improve, they typically need to be enlarged and retrained, which is resource-intensive. Upcycling pre-trained dense models into MoE models expands their capacity by adding experts focused on specific tasks, enabling learning without full retraining.
Challenges in Current Methods
Current methods for converting dense models to MoE either require continued training or starting anew, both of which are costly and time-consuming. Previous attempts lacked clarity on scaling for large models. However, sparse MoE methods offer a potential solution, though implementation details need further exploration.
NVIDIA’s Innovative Approach
Researchers from NVIDIA introduced a new way to upcycle dense models into sparse MoE models using a “virtual group” initialization and a weight scaling method. Their focus was on the Nemotron-4 model, a 15-billion-parameter multilingual model, showing improved performance after the upcycling process.
Key Techniques Used
The upcycling process involved copying the dense model’s MLP weights and applying a new routing strategy called softmax-then-topK. This technique allows tokens to be processed through a subset of experts, enhancing capacity without increasing computational costs. Weight scaling techniques were also introduced to maintain or improve accuracy.
Results of Upcycling
The upcycled Nemotron-4 model processed 1 trillion tokens, achieving a score of 67.6% on the MMLU benchmark, outperforming the continuously trained dense version, which scored 65.3%. The upcycled model also showed a 1.5% improvement in validation loss and higher accuracy, demonstrating the efficiency of this new method.
Conclusion and Key Takeaways
This research highlights that upcycling dense language models into MoE models is both feasible and efficient, leading to significant performance improvements and better resource utilization. Key findings include:
- The upcycled Nemotron-4 model achieved a 67.6% MMLU score after processing 1 trillion tokens.
- Softmax-then-topK routing improved validation loss by 1.5%.
- Upcycled models outperformed dense models without needing extra computational resources.
- Virtual group initialization and weight scaling were crucial for maintaining accuracy.
- Higher granularity MoEs, combined with careful weight scaling, significantly boosted accuracy.
In summary, this research provides a practical solution for enhancing pre-trained dense models through upcycling into MoE architectures, demonstrating how models can improve in accuracy without the costs of full retraining.
For more insights, check out the research paper. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you enjoy our work, subscribe to our newsletter and join our 50k+ ML SubReddit.
Upcoming Event
RetrieveX – The GenAI Data Retrieval Conference on Oct 17, 2023.
To evolve your company with AI and stay competitive, explore how AI can redefine your work processes. Identify automation opportunities, define KPIs, select suitable AI solutions, and implement gradually. For AI KPI management advice, contact us at hello@itinai.com. Stay updated on leveraging AI through our Telegram and Twitter channels.
Discover how AI can transform your sales processes and customer engagement at itinai.com.























