
Challenges in Large Language Models (LLMs)
The rise of large language models (LLMs) like GPT-3 and Llama brings major challenges, especially in memory usage and speed. As these models grow, they demand more computational power, making efficient hardware use crucial.
Memory and Speed Issues
Large models often require high amounts of memory and are slow in generating responses. This is especially visible with NVIDIA Hopper GPUs, where balancing memory and speed can be difficult.
Introducing Machete by Neural Magic
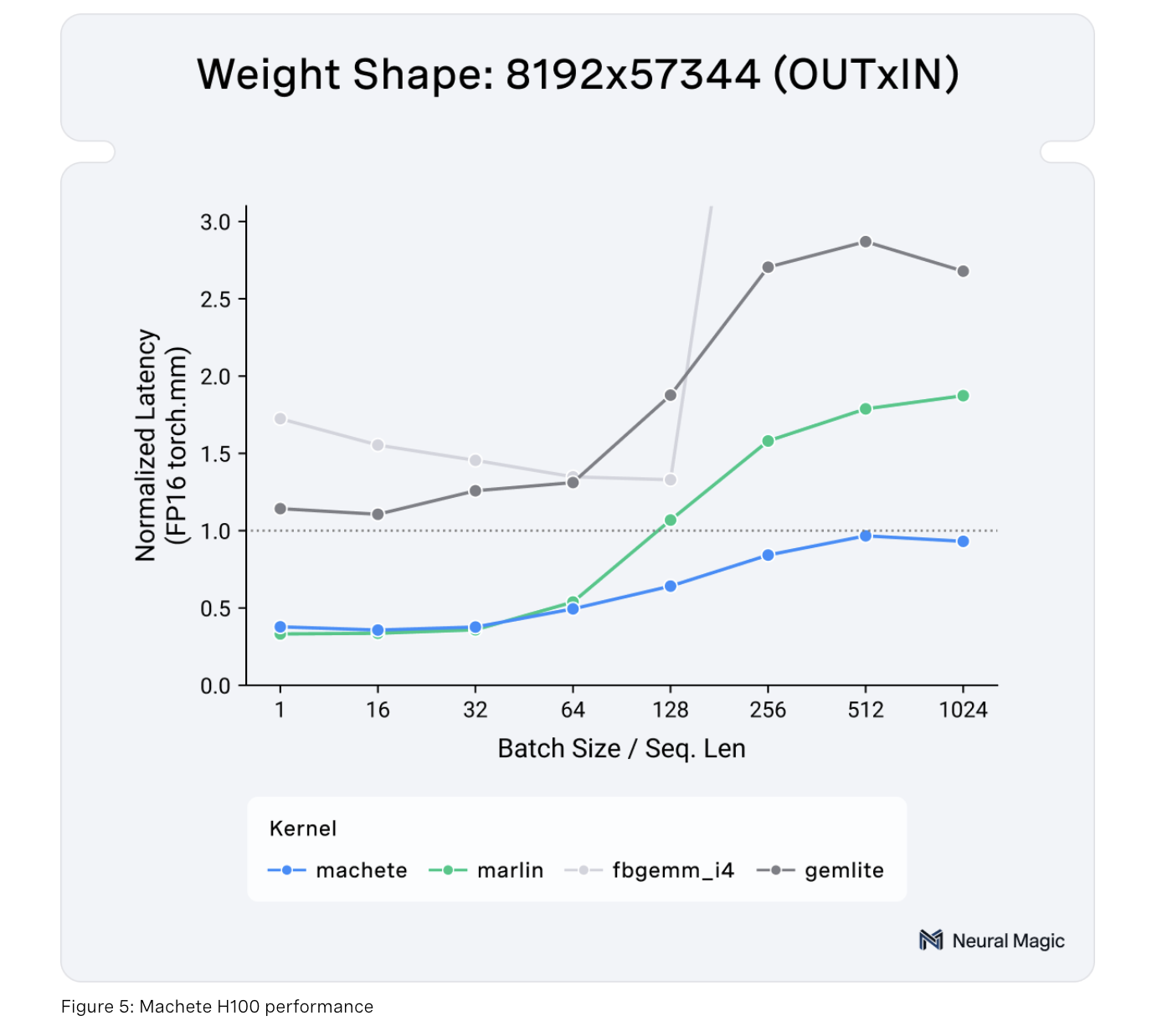
Neural Magic presents Machete, a groundbreaking mixed-input GEMM kernel for NVIDIA Hopper GPUs. Machete significantly cuts down memory usage while maintaining excellent performance.
Key Benefits of Machete
- Memory Efficiency: Reduces memory needs by approximately 4x, which is crucial for larger models.
- Speed Improvement: Matches performance of FP16 precision while being more efficient in memory use.
- Faster Inference: Enhances model inference speed, overcoming compute-bound limitations.
Technical Innovations
Machete is built on advanced technology, leveraging wgmma tensor core instructions and weight pre-shuffling to boost performance.
How Machete Works
- Weight Pre-Shuffling: Reduces memory load times, improving throughput and reducing delays.
- Upconversion Routines: Converts 4-bit elements to 16-bit efficiently, optimizing resource use.
Machete’s Value in Real-World Applications
Machete makes it possible to run large LLMs on existing hardware efficiently. In tests, it showed a 29% increase in input speed and a 32% quicker output generation for Llama 3.1 70B, achieving impressive performance metrics.
Performance Highlights
- Input Throughput: 29% faster for Llama 3.1 70B.
- Output Generation: 32% quicker rates with a response time under 250ms on a single H100 GPU.
- Scalability: 42% speed improvement when scaled to a 4xH100 setup for Llama 3.1 405B.
Conclusion
Machete stands out as a critical advancement for optimizing LLM inference on NVIDIA Hopper GPUs. By tackling memory and bandwidth issues, it streamlines the demands of large-scale models while reducing computational costs. Machete is set to transform how LLMs are deployed, delivering faster, more efficient outputs without compromising quality.
Get Connected!
For more insights and updates, follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t miss out on our newsletter and our growing ML Subreddit community.
Explore AI Solutions
To stay competitive, discover AI opportunities that can benefit your business. Connect with us for advice on implementing AI strategies.



























