
Neural Magic Releases LLM Compressor: A Novel Library to Compress LLMs for Faster Inference with vLLM
Neural Magic has launched the LLM Compressor, a cutting-edge tool for optimizing large language models. It significantly accelerates inference through advanced model compression, playing a crucial role in making high-performance open-source solutions available to the deep learning community.
Practical Solutions and Value
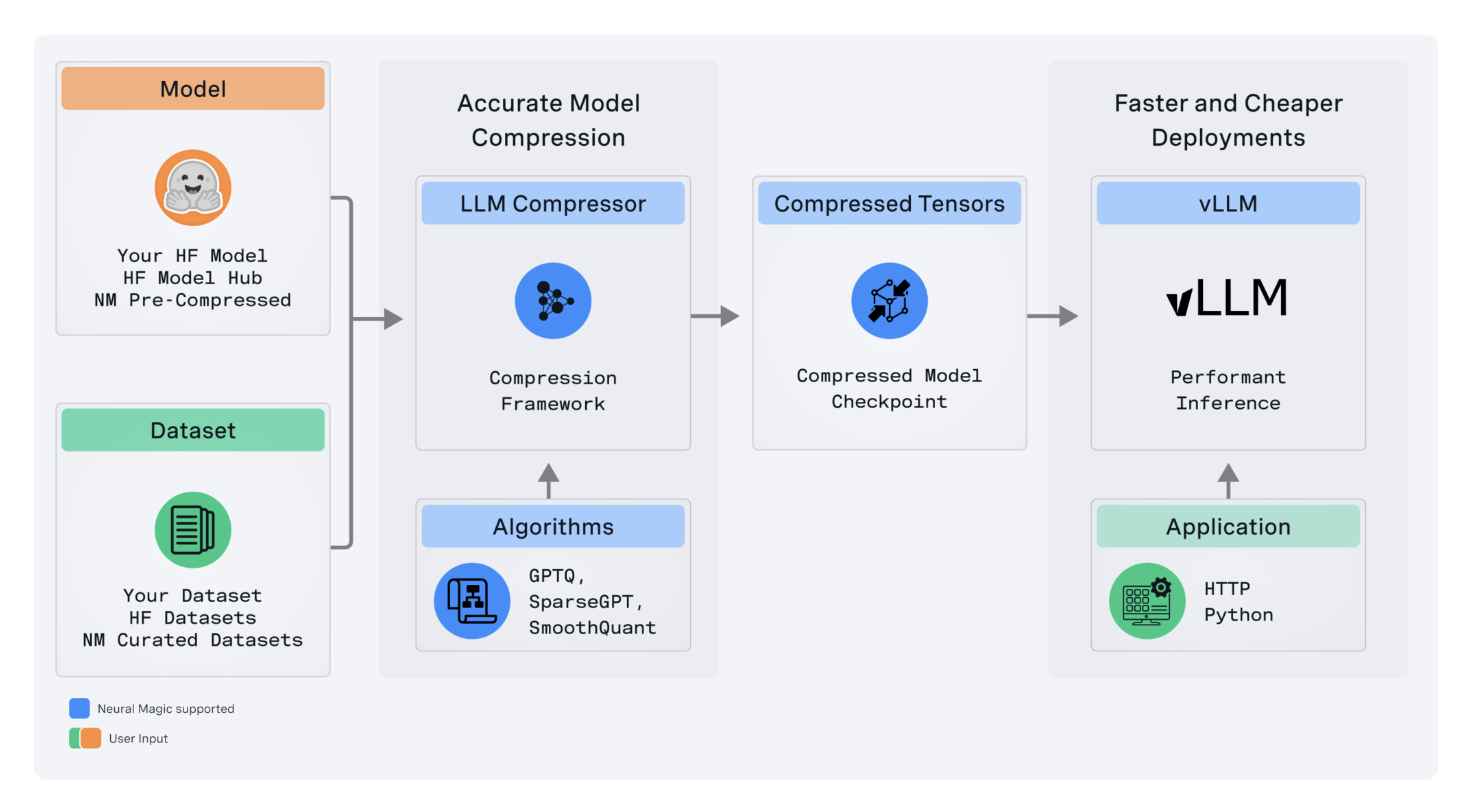
LLM Compressor reduces the complexity of model compression by consolidating fragmented tools into one library. It enables easy application of state-of-the-art compression algorithms, resulting in reduced inference latency and high accuracy, essential for production environments.
Additionally, the tool supports activation and weight quantization, maximizing performance on new GPU architectures and enabling up to a twofold increase in performance for inference tasks, especially under high server loads.
The LLM Compressor also facilitates structured sparsity and weight pruning, minimizing memory footprint and allowing deployment on resource-constrained hardware for LLMs.
Furthermore, it seamlessly integrates into open-source ecosystems like the Hugging Face model hub, providing flexibility in quantization schemes and supporting various model architectures with an aggressive roadmap for future developments.
Overall, the LLM Compressor is a vital tool for optimizing LLMs for production deployment, offering state-of-the-art features while ensuring heavy performance improvements without compromising model integrity.
For more details, visit the GitHub Page.
Evolve Your Company with AI
Discover how AI can redefine your way of work by using the Neural Magic LLM Compressor to stay competitive and improve business outcomes through AI-driven automation opportunities and sales process enhancement.
For AI KPI management advice, contact us at hello@itinai.com.
Explore AI solutions at itinai.com to redefine your sales processes and customer engagement.
























