
Practical Solutions for Efficient Long-Text Processing in LLMs
Challenges in Deployment
Large Language Models (LLMs) with extended context windows face challenges due to significant memory consumption. This limits their practical application in resource-constrained settings.
Addressing Memory Challenges
Researchers have developed various methods to address KV cache memory challenges in LLMs, such as sparsity exploration, learnable token selection, and efficient attention mechanisms.
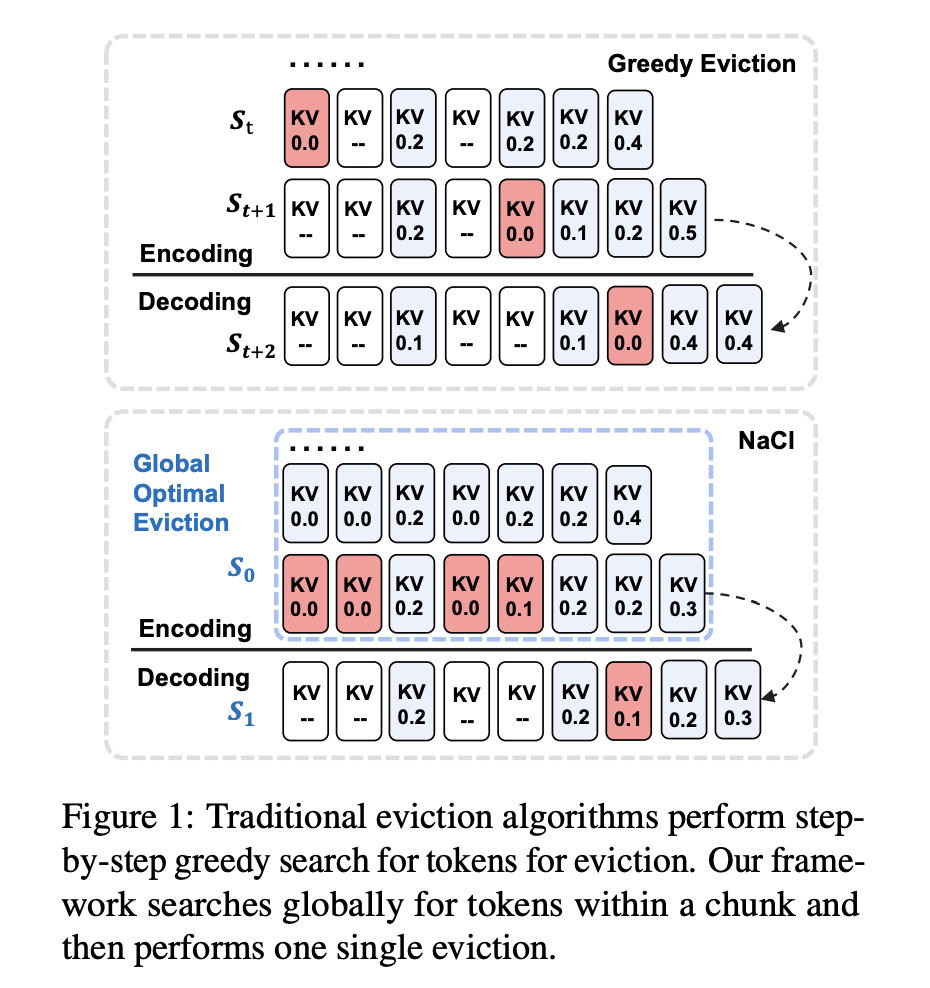
Introducing NACL Framework
NACL is a unique KV cache eviction framework for LLMs, focusing on the encoding phase rather than generation. It aims to enhance long-context modeling performance while efficiently managing memory constraints in LLMs.
Hybrid KV Cache Eviction Policy
NACL introduces a hybrid KV cache eviction policy combining PROXY-TOKENS EVICTION and RANDOM EVICTION methods to optimize token retention and enhance robustness.
Performance and Effectiveness
NACL demonstrates impressive performance in both short-text and long-text scenarios while managing the KV cache under constrained memory budgets. It shows stable performance across different budget settings, even surpassing full cache performance in some tasks like HotpotQA and QMSum.
Impact and Future Work
NACL significantly improves cache eviction strategies, reduces inference memory costs, and minimizes impact on LLM task performance. This research contributes to optimizing LLM efficiency, potentially enabling longer text processing with fewer computational resources.
AI Solutions for Business
Discover how AI can redefine your way of work and sales processes. Identify automation opportunities, define KPIs, select an AI solution, and implement gradually to leverage AI for business success.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com. For updates, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.























