
Practical Solutions and Value of MuxServe for Efficient LLM Serving
Efficient Serving of Multiple Large Language Models (LLMs)
Large Language Models (LLMs) have transformed various applications like chat, programming, and search. However, serving multiple LLMs efficiently presents challenges due to substantial computational requirements.
Challenges and Existing Solutions
The substantial computational requirements of LLMs result in inefficient resource utilization. Existing methods like spatial partitioning and deep learning serving systems fall short in addressing efficient multi-LLM serving.
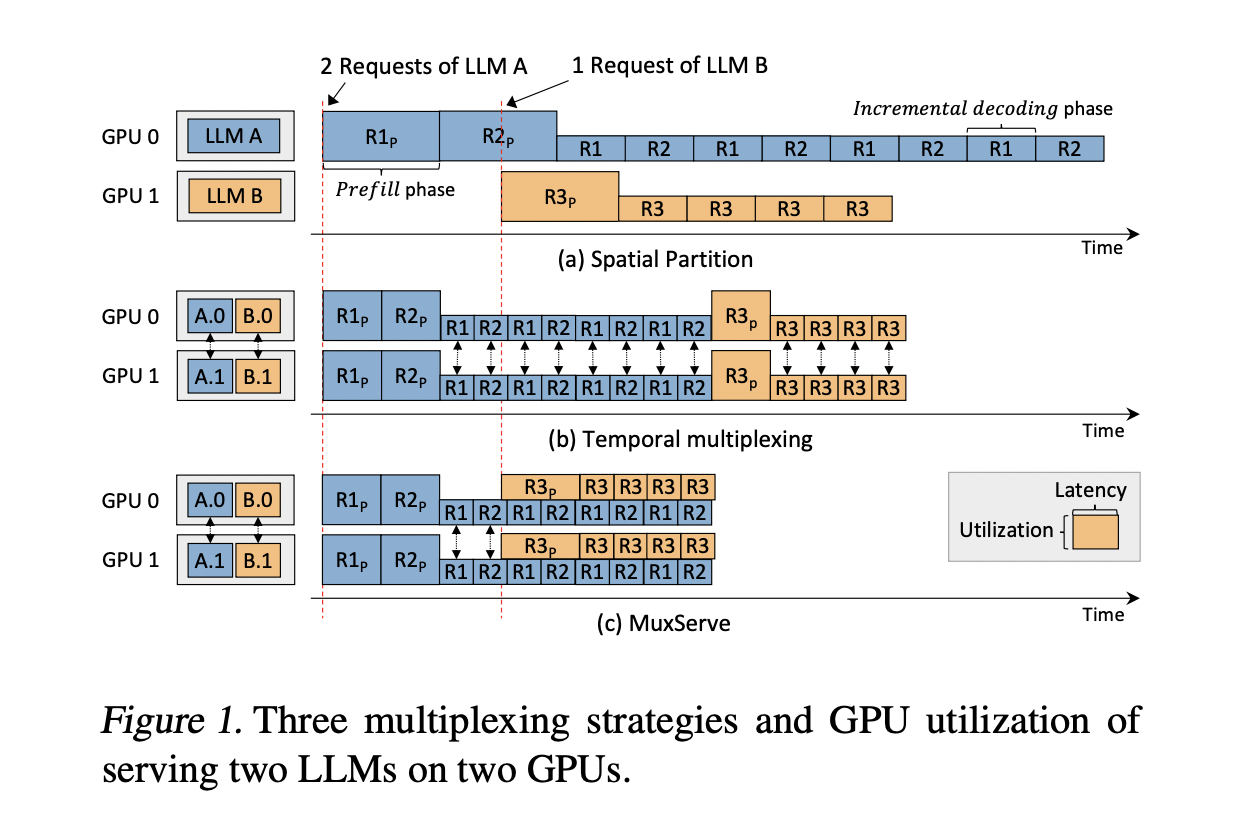
MuxServe: A Flexible and Efficient Solution
MuxServe presents a flexible spatial-temporal multiplexing approach to efficiently serve multiple LLMs. It optimizes GPU utilization, throughput, and request processing, offering up to 1.8× higher throughput than existing systems.
Performance and Benefits
MuxServe demonstrates superior performance, achieving higher throughput and better service level objective (SLO) attainment across various workload scenarios. Its ability to adapt to different LLM sizes and request patterns makes it a versatile solution for efficient and scalable LLM serving.
Impact and Future of AI with MuxServe
By leveraging MuxServe, companies can redefine their way of work, stay competitive, and efficiently serve multiple LLMs concurrently. This system provides a promising framework for the evolving demands of LLM deployment in the AI industry.
Learn More and Get in Touch
Check out the Paper and Project. For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com or stay tuned on our Telegram or Twitter.
AI Solutions for Your Company
Discover how AI can redefine your way of work, identify automation opportunities, define KPIs, select an AI solution, and implement gradually to stay competitive and evolve with AI. Connect with us at hello@itinai.com for AI KPI management advice and continuous insights into leveraging AI.























