
Enhancing Training Efficiency with Muon Optimizer
Understanding the Grokking Phenomenon
In recent years, researchers have investigated a phenomenon known as “grokking,” where AI models experience a delayed transition from memorization to generalization. Initially noted in basic algorithmic tasks, grokking allows models to achieve high training accuracy while still underperforming on validation tasks for extended periods. This sudden shift towards generalization is crucial for interpreting models and enhancing training efficiency. Previous studies have pointed to the importance of weight decay and regularization, but the specific impact of different optimizers has not been thoroughly examined.
The Role of Optimizers in Grokking
A recent study by Microsoft explored how different optimizers affect grokking behavior. It specifically compared the popular AdamW optimizer with a newer algorithm called Muon. The study aimed to determine whether Muon’s unique features could speed up the generalization process.
Experimental Framework
- The research tested seven algorithmic tasks, primarily focusing on modular arithmetic and parity classification.
- Modern Transformer architecture was used for all tasks to effectively illustrate grokking under optimal training conditions.
Architecture and Optimization Techniques
The model used a standard Transformer design implemented in the PyTorch framework. Key features included:
- Multi-head self-attention
- Rotary positional embeddings (RoPE)
- Normalization and activation layers
What distinguished the optimizers was their operational mechanics:
- AdamW: Utilizes adaptive learning rates with a decoupled approach to weight decay.
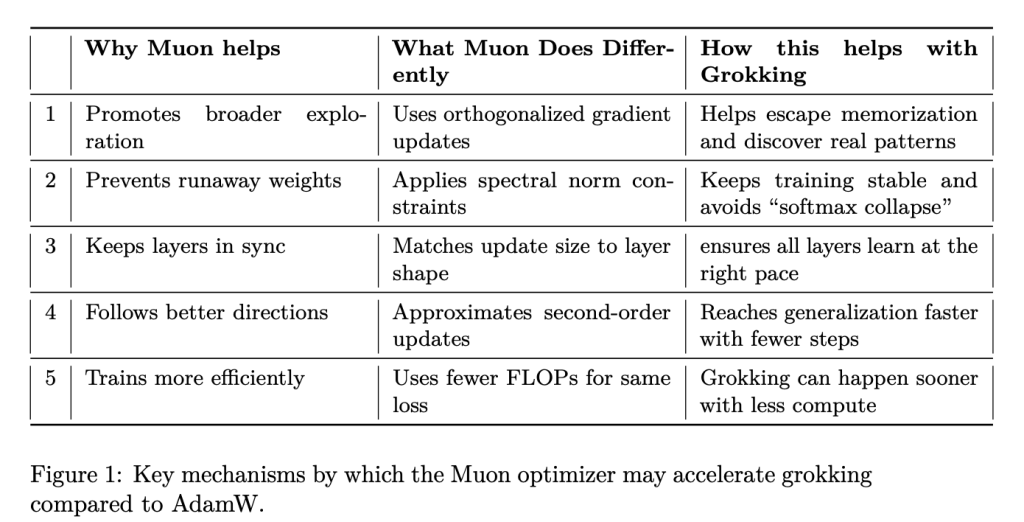
- Muon: Implements orthogonal gradients, spectral norm constraints for training stability, and approximates second-order curvature for more informed updates, promoting efficient training.
Impact of Softmax Variants
The study also evaluated different softmax configurations (standard softmax, stablemax, sparsemax) to ascertain their effects on training dynamics. This ensured that observed results were primarily due to optimizer behaviors rather than output activation differences.
Results and Findings
The empirical evaluations were rigorously designed, assessing multiple combinations of optimizers and tasks across various initial conditions to ensure reliability. The study established grokking as the moment when validation accuracy exceeds 95% after training stabilization.
Key Results
- Muon consistently outperformed AdamW, achieving the grokking threshold in an average of 102.89 epochs compared to AdamW’s 153.09 epochs.
- This difference was statistically significant (t = 5.0175, p ≈ 6.33e−8).
- Muon demonstrated tighter distributions of grokking epochs, indicating more predictable training outcomes.
All tasks were conducted on NVIDIA H100 GPUs, ensuring a controlled and consistent environment for analysis.
Conclusion and Strategic Recommendations
The findings from this research emphasize the significant role that optimizer choice plays in facilitating model generalization. By employing second-order updates and spectral norm constraints, Muon appears to offer a more effective pathway for AI models to navigate training phases and avoid prolonged periods of overfitting.
Businesses should consider optimization strategies as a fundamental aspect of their AI development process. While previous work has focused on data management and regularization efforts, it is clear that the architecture of the optimizer can dramatically influence training dynamics.
Summary
Incorporating the Muon optimizer could significantly enhance the efficiency and effectiveness of AI model training, leading to faster generalization and reduced overfitting. Businesses are encouraged to re-evaluate their optimization strategies alongside data and regularization approaches to fully leverage the potential of AI technology in their operations.





















