
Moonsight AI Unveils Kimi-VL: Innovative Solutions for Multimodal AI
Moonsight AI has launched Kimi-VL, an advanced vision-language model series designed to enhance the capabilities of artificial intelligence in processing and reasoning across multiple data formats, such as images, text, and videos. This development addresses significant gaps in existing multimodal systems, particularly in effective long-context understanding and high-resolution visual processing.
Understanding Multimodal AI
Multimodal AI systems are essential for analyzing and interpreting diverse input types in real time. Unlike traditional language models that excel with textual data, Kimi-VL is engineered to decode both language and visual cues simultaneously. This feature enables improved contextual awareness, reasoning depth, and adaptability, which are crucial for various applications, including:
- Real-time task assistance
- User interface analysis
- Academic material understanding
- Complex scene interpretation
Challenges in Current Multimodal Systems
Many existing multimodal systems struggle with:
- Processing long contexts effectively
- Generalizing across high-resolution inputs
- Maintaining performance without requiring extensive computational resources
These limitations lead to challenges in real-world applications, particularly with complex tasks such as OCR-based document analysis and mathematical problem-solving. Historical models, while innovative, have often lacked the scalability and flexibility needed to tackle these challenges comprehensively.
The Kimi-VL Solution
Kimi-VL represents a breakthrough in multimodal AI, utilizing a mixture-of-experts (MoE) architecture that activates only 2.8 billion parameters during inference, ensuring efficiency and performance. Key features include:
- A native-resolution visual encoder, MoonViT, capable of processing high-resolution images without fragmentation.
- Support for context windows of up to 128,000 tokens, achieving 100% recall for up to 64,000 tokens.
- Enhanced reasoning capabilities through the Kimi-VL-Thinking variant, designed for long-horizon reasoning tasks.
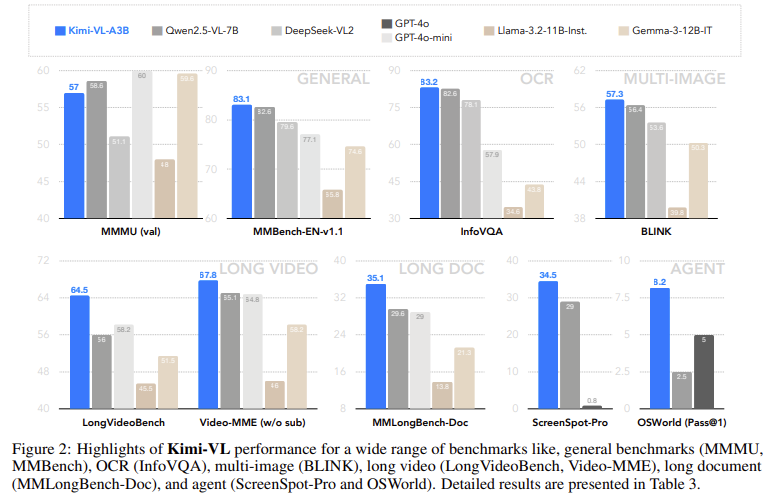
Performance and Benchmarking
Kimi-VL has demonstrated exceptional performance across multiple benchmarks, including:
- 64.5 on the LongVideoBench
- 35.1 on MMLongBench-Doc
- 83.2 on InfoVQA
- 34.5 on ScreenSpot-Pro
Moreover, Kimi-VL-Thinking excelled in reasoning-intensive benchmarks, scoring:
- 61.7 on MMMU
- 36.8 on MathVision
- 71.3 on MathVista
Key Takeaways
- Kimi-VL activates only 2.8 billion parameters during inference, ensuring efficiency.
- MoonViT processes high-resolution images for improved clarity in OCR and UI interpretation tasks.
- The model supports a vast context of up to 128,000 tokens while maintaining high accuracy rates.
- Kimi-VL-Thinking consistently outperforms larger models in reasoning tasks.
- Total pre-training involved 4.4 trillion tokens across diverse multimodal datasets.
Conclusion
In summary, Kimi-VL by Moonsight AI sets a new standard for multimodal AI systems. Its innovative architecture and efficient processing capabilities make it a powerful tool for businesses seeking to enhance their operational efficiency through artificial intelligence. By integrating such advanced technologies, organizations can automate processes, improve customer interactions, and drive significant value in their operations.
For further insights on leveraging artificial intelligence in your business, please contact us at hello@itinai.ru.























