
Understanding Retrieval-Augmented Generation (RAG)
Large Language Models (LLMs) are essential for answering complex questions. They use advanced techniques to improve how they find and generate responses. One effective method is Retrieval-Augmented Generation (RAG), which enhances the accuracy and relevance of answers by retrieving relevant information before generating a response. This process allows LLMs to cite sources, reducing misinformation and making it easier to verify facts.
Example of RAG in Action
A prime example of a RAG system is Microsoft’s Bing Search. It enhances the reliability of responses by integrating retrieval and grounding techniques to cite sources. However, most RAG models focus on English, limiting their effectiveness in multilingual contexts.
Evaluating RAG Systems
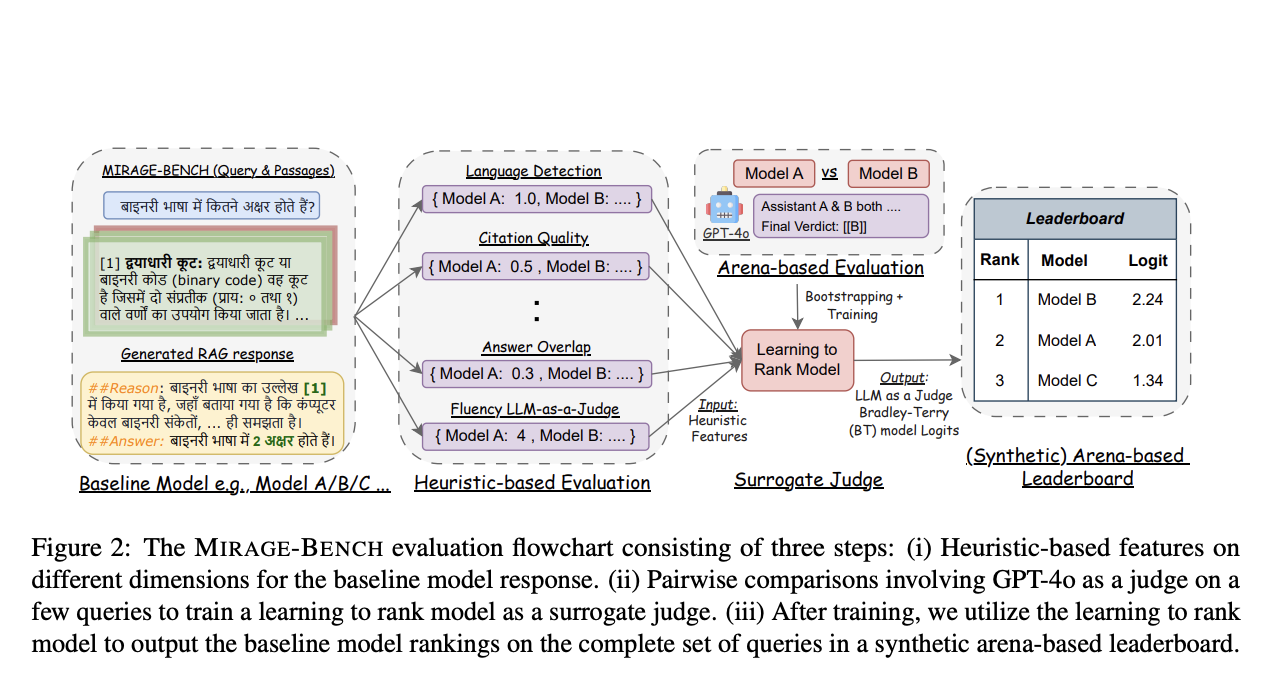
There are two main ways to assess RAG systems:
- Heuristic-based benchmarks: These use various computational measures but rely on human judgment for comparison, making it hard to rank models clearly.
- Arena-based benchmarks: These compare model outputs directly, but they can be expensive and resource-intensive, especially with many models.
Introducing MIRAGE-BENCH
A research team from the University of Waterloo and VECTARA has developed MIRAGE-BENCH to address the limitations of existing benchmarks. This new framework offers a cost-effective way to evaluate multilingual generation across 18 languages. It utilizes a retrieval dataset called MIRACL, which includes relevant Wikipedia sections and human-curated questions.
Key Features of MIRAGE-BENCH
- It assesses responses using seven important factors, such as fluency and citation quality.
- It employs a Machine Learning model to act as a surrogate judge, allowing for efficient scoring without needing a costly LLM each time.
- This method adapts to new evaluation standards and has shown high correlation with expensive models like GPT-4o.
Benefits of MIRAGE-BENCH
MIRAGE-BENCH has proven beneficial for smaller LLMs and enhances the efficiency of multilingual RAG benchmarks. This opens up opportunities for more comprehensive evaluations across various languages.
Contributions of the Research Team
- Creation of MIRAGE-BENCH to advance multilingual RAG research.
- Development of a trainable model that balances efficiency and accuracy in evaluations.
- Analysis of the strengths and weaknesses of 19 multilingual LLMs.
Get Involved
For more insights, check out the research paper and follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Transform Your Business with AI
Stay competitive by leveraging MIRAGE-BENCH and other AI solutions:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Explore AI Solutions
Discover how AI can enhance your sales processes and customer engagement at itinai.com.



























