
Introduction to Multimodal Large Language Models (MLLMs)
Multimodal large language models (MLLMs) are advancing rapidly in AI. They combine vision and language processing to improve understanding and interaction with different types of data. These models are effective in tasks like image recognition and natural language understanding by integrating visual and textual data. This capability is especially useful in areas like autonomous navigation, medical imaging, and remote sensing, where analyzing both visual and textual information is crucial.
Challenges of MLLMs
Despite their benefits, MLLMs have significant limitations. They require a lot of computational power and have many parameters, making them hard to use on devices with limited resources. Many MLLMs depend on general training data from the internet, which can hinder their performance in specialized fields. This reliance creates barriers for tasks that need detailed, domain-specific knowledge, especially in complex areas like remote sensing and autonomous driving.
Current Limitations
Current MLLMs often use vision encoders like CLIP to connect visual data with language models. However, they struggle in specialized domains due to insufficient visual knowledge. Adapting these models for different fields can be inefficient and challenging, especially for smaller devices.
Introducing Mini-InternVL
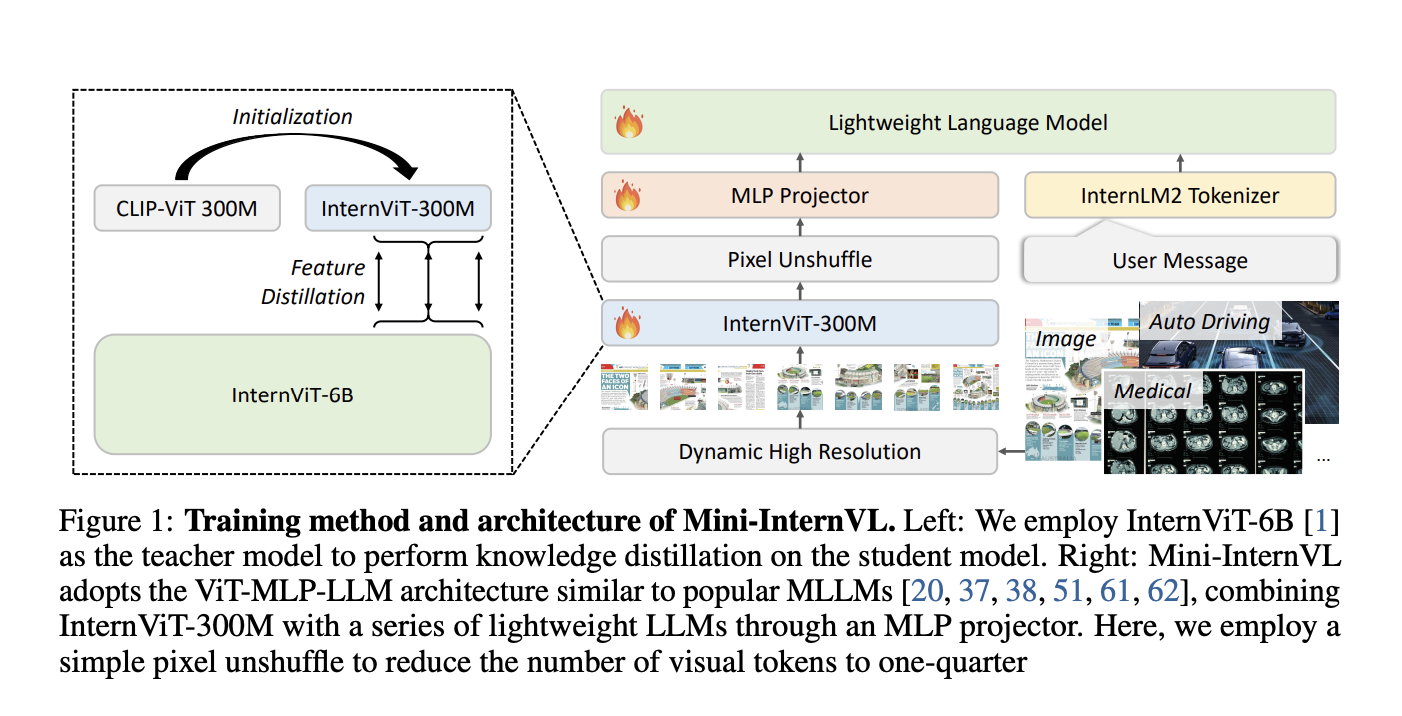
Researchers from several prestigious institutions have developed Mini-InternVL, a series of lightweight MLLMs with parameters ranging from 1 billion to 4 billion. This model aims to maintain 90% of the performance of larger models while using only 5% of the parameters, making it efficient and accessible for everyday devices. Mini-InternVL is designed for tasks like autonomous driving, medical imaging, and remote sensing, all while requiring less computational power than traditional MLLMs.
Key Features of Mini-InternVL
- Robust Vision Encoder: Mini-InternVL uses a vision encoder called InternViT-300M, which enhances its ability to transfer knowledge across domains with fewer resources.
- Multiple Variants: The series includes Mini-InternVL-1B, Mini-InternVL-2B, and Mini-InternVL-4B, allowing for flexible deployment based on needs.
- Two-Stage Training: The model undergoes language-image alignment and visual instruction tuning, improving its adaptability to real-world tasks.
Performance Achievements
Mini-InternVL has shown impressive results on various benchmarks, achieving up to 90% of the performance of larger models with only 5% of their parameters. For example, Mini-InternVL-4B scored 78.9 on MMBench and 81.5 on ChartQA, excelling in both general and domain-specific tasks. In autonomous driving, it matched the accuracy of more resource-intensive models, showcasing its efficiency in medical imaging and remote sensing as well.
Conclusion
Mini-InternVL successfully addresses the high computational demands of multimodal models. It demonstrates that efficient design and training methods can lead to competitive performance while reducing resource needs. With a unified adaptation framework and a strong vision encoder, Mini-InternVL offers a scalable solution for specialized applications in resource-limited environments.
Get Involved
Check out the Paper and Model Card on Hugging Face. Follow us on Twitter, join our Telegram Channel, and LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Transform Your Business with AI
To stay competitive, leverage Mini-InternVL for your business. Here’s how:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram or Twitter.

























