
Understanding Text Embedding in AI
Text embedding is a key part of natural language processing (NLP). It turns words and phrases into numerical vectors that capture their meanings. This allows machines to handle tasks like classification, clustering, retrieval, and summarization. By converting text into vectors, machines can better understand human language, improving applications such as sentiment analysis and recommendation systems.
The Challenge of Training Data
A major issue in text embedding is the need for large amounts of high-quality training data. Manually labeling this data is both costly and time-consuming. While creating synthetic data is a potential fix, many techniques rely on expensive proprietary models like GPT-4. This reliance can limit access to advanced embedding technologies for researchers.
Current Methods and Their Limitations
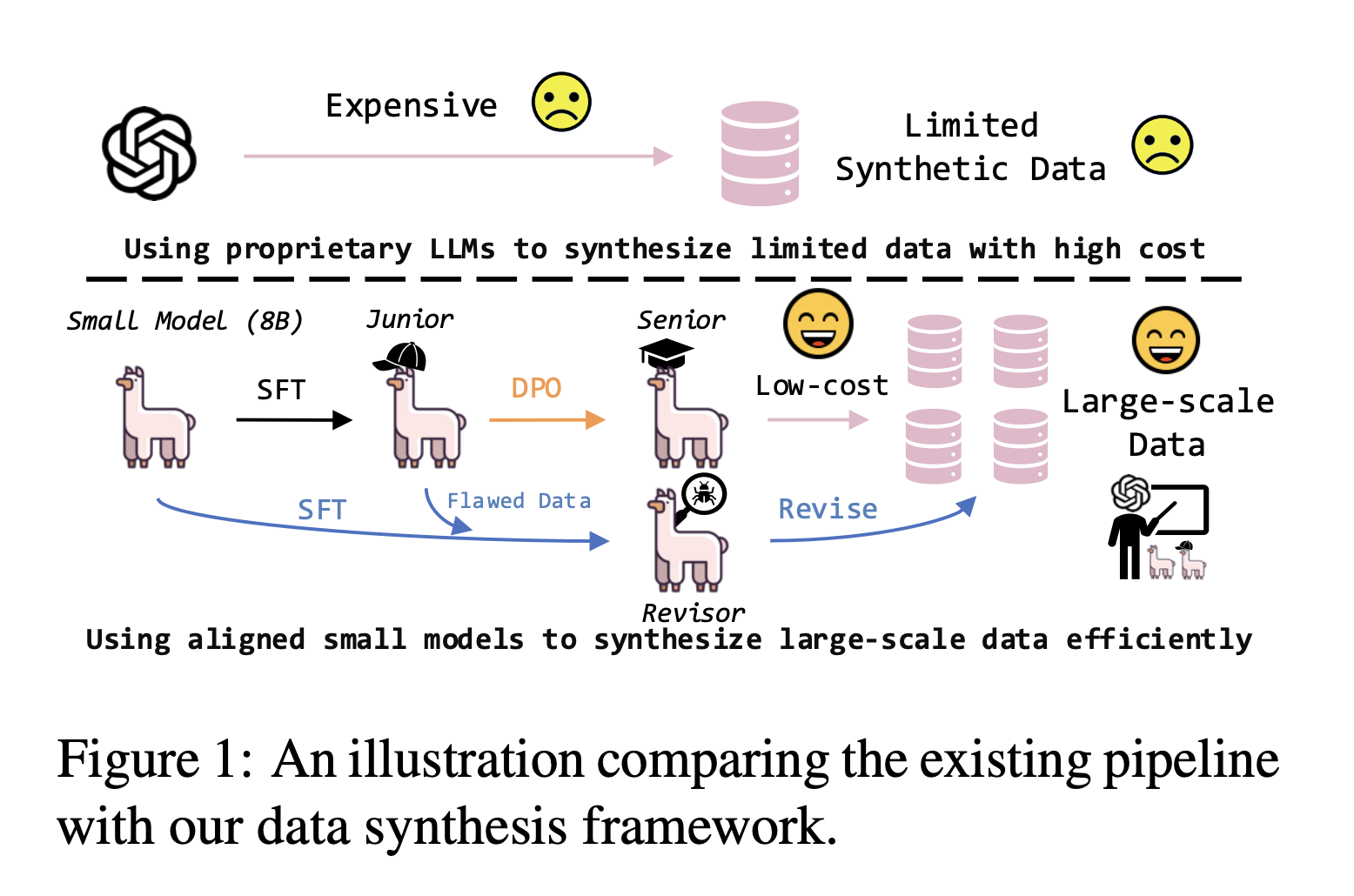
Many current methods use large language models (LLMs) to generate synthetic text. For example, GPT-4 creates triplets—queries with positive and negative examples—to generate diverse data. However, this process can be costly and complex, making it hard for researchers to tailor it to their needs. There’s a clear need for more accessible and cost-effective solutions.
Introducing SPEED: A New Framework
Researchers from the Gaoling School of Artificial Intelligence and Microsoft have developed SPEED, a framework that uses small, open-source models to create high-quality embedding data with much lower resource needs. This innovative approach aims to make synthetic data generation more accessible.
How SPEED Works
SPEED consists of three main components:
- Junior Generator: Produces initial low-cost synthetic data based on task descriptions.
- Senior Generator: Enhances data quality using preference optimization.
- Data Revisor: Refines outputs to improve quality and consistency.
This process enables SPEED to efficiently align small models with tasks typically handled by larger models.
Results and Benefits of SPEED
SPEED has shown remarkable improvements in embedding quality and cost-effectiveness. It outperformed the leading model, E5mistral, using only 45,000 API calls compared to E5mistral’s 500,000, achieving a cost reduction of over 90%. On the Massive Text Embedding Benchmark (MTEB), SPEED performed exceptionally across various tasks, demonstrating its versatility and effectiveness.
Practical Solutions and Value of SPEED
SPEED provides a practical, low-cost solution for the NLP community. It allows researchers to generate high-quality data for training embedding models without relying on expensive proprietary technologies. This framework showcases how small, open-source models can efficiently meet the demands of synthetic data generation, fostering broader access to advanced NLP tools.
Get Involved and Stay Updated
Check out the Paper for more details. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. If you appreciate our work, subscribe to our newsletter and join our 55k+ ML SubReddit.
Enhance Your Business with AI
To evolve your company with AI, consider the following steps:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or Twitter.























