
Advancements in Large Language Models (LLMs)
Recent developments in large language models (LLMs) such as DeepSeek-R1, Kimi-K1.5, and OpenAI-o1 have demonstrated remarkable reasoning capabilities. However, the lack of transparency regarding training code and datasets, particularly with DeepSeek-R1, raises concerns about replicating these models effectively. To improve our understanding of LLMs, there is a pressing need for targeted datasets that allow for controlled complexity, which can help isolate variables in reasoning studies.
Enhancing Reasoning Capabilities
Techniques like Chain-of-Thought (CoT) reasoning have been pivotal in simplifying complex problems into manageable tasks. Additionally, adaptations of Monte Carlo Tree Search (MCTS) are being used to improve model-based planning by balancing exploration and exploitation. Post-training enhancements, including fine-tuning and reinforcement learning (RL) on specialized datasets, are showing promise. Notable methods such as Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and REINFORCE++ are at the forefront of advancing reasoning in LLMs.
Logic-RL Framework
Researchers from Microsoft Research Asia and Ubiquant have introduced Logic-RL, a rule-based RL framework that learns reasoning patterns through logic puzzles. Utilizing the REINFORCE++ algorithm, Logic-RL allows the model to focus more on reasoning as it trains, leading to improved performance. Their findings indicate that using just 5,000 generated logic puzzles, the model achieved significant improvements in cross-domain generalization, suggesting that RL can foster abstract problem-solving skills.
Challenges and Improvements
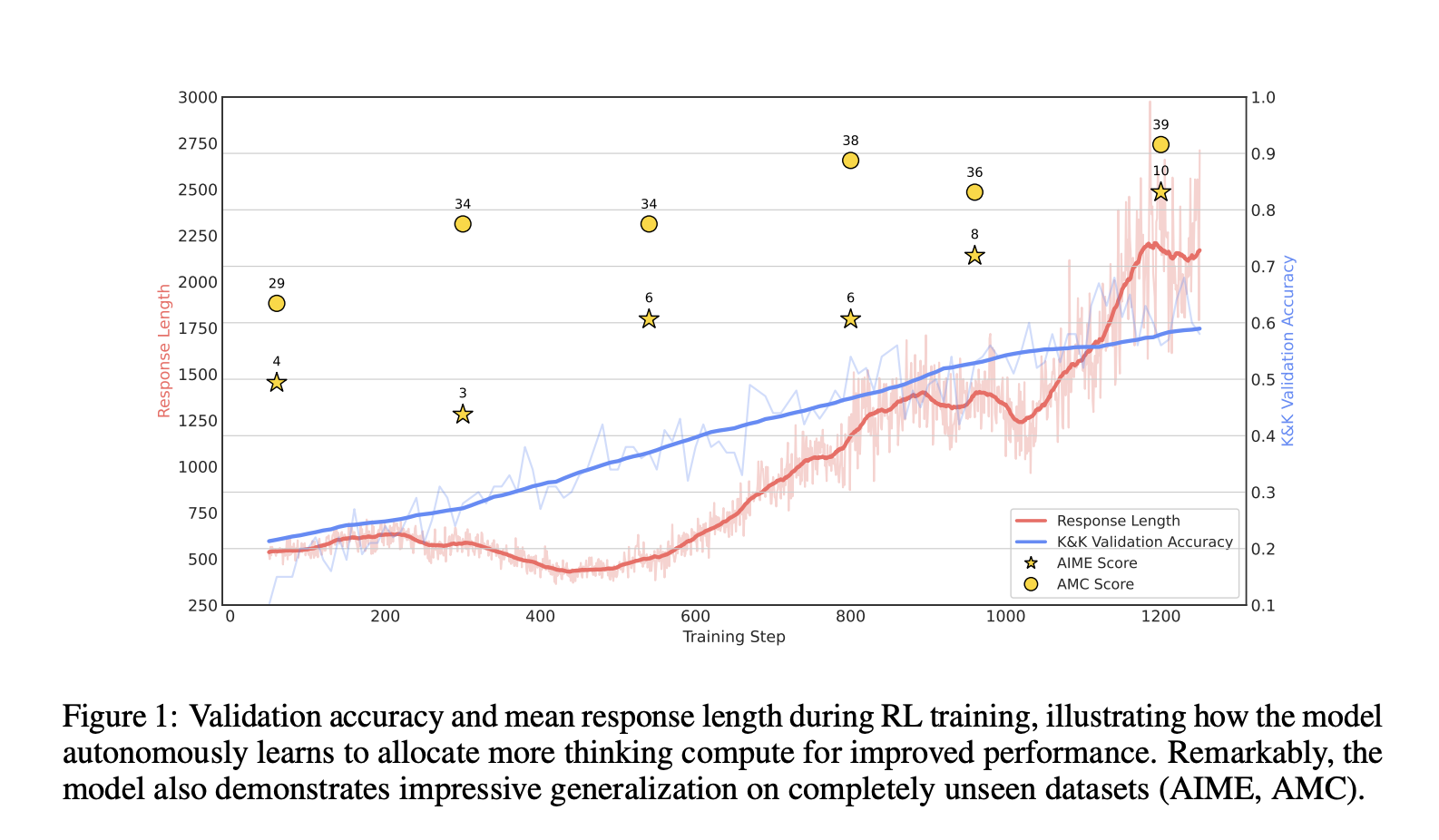
Despite the advancements, challenges remain, such as the Qwen2.5-Math-7B model’s tendency to generate conflicting Python code blocks. Testing results show that both Qwen2.5-7B-Base and Qwen2.5-7B-Instruct achieved similar training metrics during RL training, yet the improvements in reasoning capabilities were substantial. The output length increased from an average of 500 tokens to approximately 2,000 tokens after 1,000 RL training steps, enabling the model to explore complex solutions effectively.
Comparative Performance of Algorithms
While PPO demonstrated strong accuracy and reward, it was significantly slower than REINFORCE++ in training speed. REINFORCE++ provided better stability and efficiency compared to Group Relative Policy Optimization (GRPO), which performed the weakest among the evaluated algorithms. The model’s strong out-of-distribution (OOD) generalization capabilities were highlighted, showing substantial improvements across various datasets.
Future Research Directions
The potential of Logic-RL in developing complex reasoning skills is evident, yet the findings are based on a limited dataset, restricting their broader applicability. Future research should aim to apply this framework to more diverse datasets to validate its effectiveness across various domains. By keeping this work open, researchers hope to contribute to the wider scientific community.
Practical Business Solutions
Explore how AI can transform business operations:
- Identify processes that can be automated to enhance efficiency.
- Determine key performance indicators (KPIs) to measure the impact of AI investments.
- Select customizable tools that align with your business objectives.
- Start with small AI projects, evaluate their effectiveness, and scale gradually.
For guidance on managing AI in your business, contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.

























