
Understanding Edge Devices and AI Integration
Edge devices such as smartphones, IoT devices, and embedded systems process data right where it is generated. This practice enhances privacy, lowers latency, and improves responsiveness. However, implementing large language models (LLMs) on these devices is challenging due to their high computational and memory requirements.
The Challenge of LLMs
LLMs are massive and demand significant resources, often exceeding what most edge devices can handle. Traditional methods use high-bit precision formats like FP32 and FP16, which, while stable, require extensive memory and energy. Although some techniques try lower-bit quantization to alleviate these issues, they often face compatibility challenges with existing hardware. Other methods, like dequantization, can slow down processes, negating any efficiency gains.
Microsoft’s Innovative Solutions
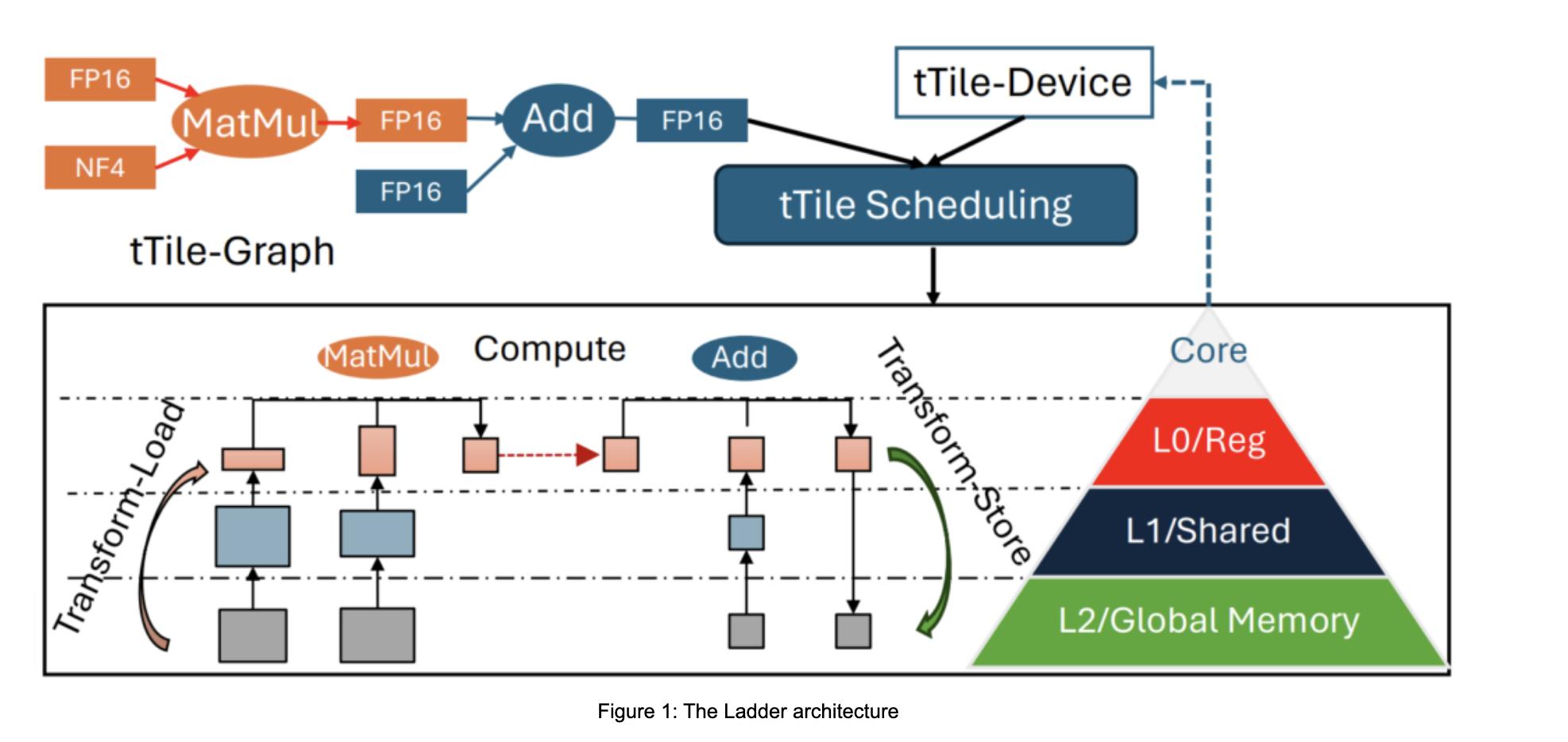
Microsoft researchers have developed new techniques to make low-bit quantization of LLMs efficient on edge devices. Their approach involves:
- Ladder Data Type Compiler: This tool helps align low-bit model formats with hardware capabilities, ensuring performance isn’t compromised.
- T-MAC mpGEMM Library: This library enhances mixed-precision computations, improving efficiency by avoiding traditional multiplication methods.
- LUT Tensor Core Hardware Architecture: This specialized hardware accelerates low-bit calculations while consuming less power.
Real-World Impact
The Ladder compiler can outperform typical deep neural network compilers by up to 14.6 times in specific tasks. On devices like the Surface Laptop, the T-MAC library achieved remarkable speeds, demonstrating substantial improvements in efficiency even on lower-end devices like the Raspberry Pi 5.
Key Benefits of the Research
- Low-bit quantization reduces model sizes, enabling better performance on edge devices.
- The T-MAC library speeds up inference by streamlining operations.
- The Ladder compiler ensures compatibility with modern hardware.
- Optimized techniques cut down power consumption, making LLMs viable for energy-efficient devices.
Conclusion
This research is a significant step toward effective LLM deployment on a variety of devices, from powerful laptops to energy-efficient IoT solutions. By addressing issues of memory, efficiency, and compatibility, Microsoft has made the future of AI applications brighter and more accessible.
Get Involved!
For further details, check out the full research paper. Stay updated by following us on Twitter, joining our Telegram Channel, or participating in our LinkedIn Group. Don’t miss out on our growing community of over 75,000 members on our ML SubReddit.
























