
Understanding Long-Context LLMs
Long-context LLMs are powerful tools that support advanced functions like analyzing code repositories, answering questions in lengthy documents, and enabling many-shot learning. They can handle extensive context windows, ranging from 128K to 10M tokens. However, they face challenges with memory usage and computing efficiency during inference.
Optimizing Performance
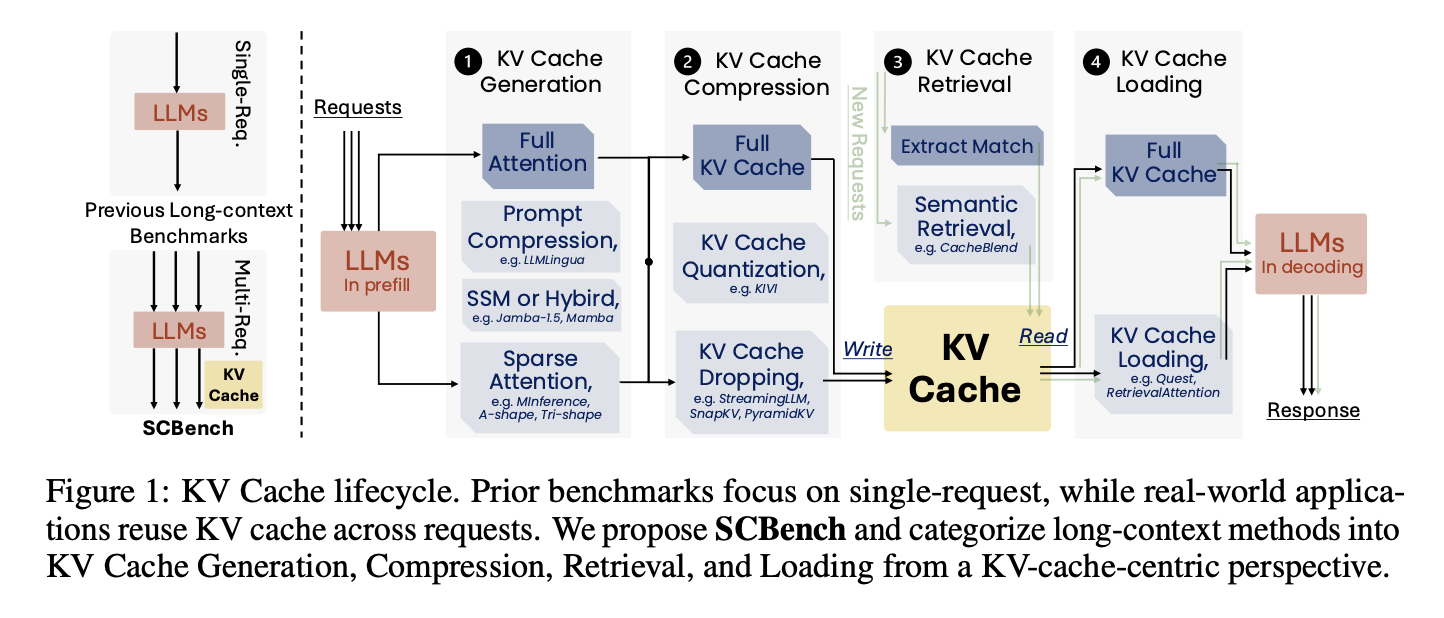
To tackle these challenges, optimizations using Key-Value (KV) cache focus on improving cache reuse for multi-turn interactions. Techniques such as PagedAttention, RadixAttention, and CacheBlend aim to lower memory costs but are often tested in single-turn scenarios, missing practical multi-turn applications.
Efforts to Enhance Long-Context Inference
Research is directed towards reducing computational and memory issues during pre-filling and decoding. Methods like sparse attention, linear attention, and prompt compression help manage large contexts. Strategies for decoding, including static and dynamic KV compression, aim to optimize memory management. While these methods improve efficiency, they often rely on lossy techniques that can hinder performance in multi-turn situations.
Introducing SCBench
Researchers from Microsoft and the University of Surrey developed SCBench, a benchmark to evaluate long-context methods in LLMs with a focus on KV cache. It assesses four KV cache stages: generation, compression, retrieval, and loading across 12 tasks and two modes: multi-turn and multi-request.
Evaluating Long-Context LLMs
The framework categorizes long-context methods, analyzing performance in tasks like string retrieval and multitasking. The benchmark reveals that O(n) memory approaches perform well in multi-turn contexts, while sub-O(n) methods face challenges.
Key Findings from Research
Six open-source long-context LLMs, including Llama-3.1 and GLM-4, were evaluated. The study tested eight solutions like sparse attention and KV cache management. Key findings include:
- MInference excelled in retrieval tasks.
- A-shape and Tri-shape performed well in multi-turn tasks.
- KV and prompt compression methods had mixed results.
- SSM-attention hybrids struggled in multi-turn interactions.
Conclusion
The research highlights a significant gap in evaluating long-context methods, particularly in multi-turn scenarios. The SCBench benchmark fills this gap, assessing methods throughout the KV cache lifecycle. It offers valuable insights for enhancing long-context LLMs and architectures, focusing on practical applications in the real world.
Explore Further
Check out the Paper and Dataset. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t miss our 60k+ ML SubReddit.
Transform Your Business with AI
Stay competitive by leveraging the insights from Microsoft AI and SCBench. Here’s how AI can improve your operations:
- Identify Automation Opportunities: Find key areas in customer interactions where AI can help.
- Define KPIs: Ensure measurable impacts from your AI efforts.
- Select an AI Solution: Choose tools that fit your needs and can be customized.
- Implement Gradually: Start with a pilot program, gather data, and expand carefully.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Revolutionize Your Sales and Customer Engagement
Discover innovative AI solutions at itinai.com.

























