
Practical Solutions and Value of Michelangelo AI Framework
Challenges in Long-Context Reasoning
Long-context reasoning in AI requires models to understand complex relationships within vast datasets beyond simple retrieval tasks.
Limitations of Existing Methods
Current evaluation methods often focus on isolated retrieval capabilities rather than synthesizing information from large datasets.
Introducing Michelangelo Framework
Michelangelo introduces Latent Structure Queries to evaluate models’ ability to synthesize scattered data points across lengthy datasets.
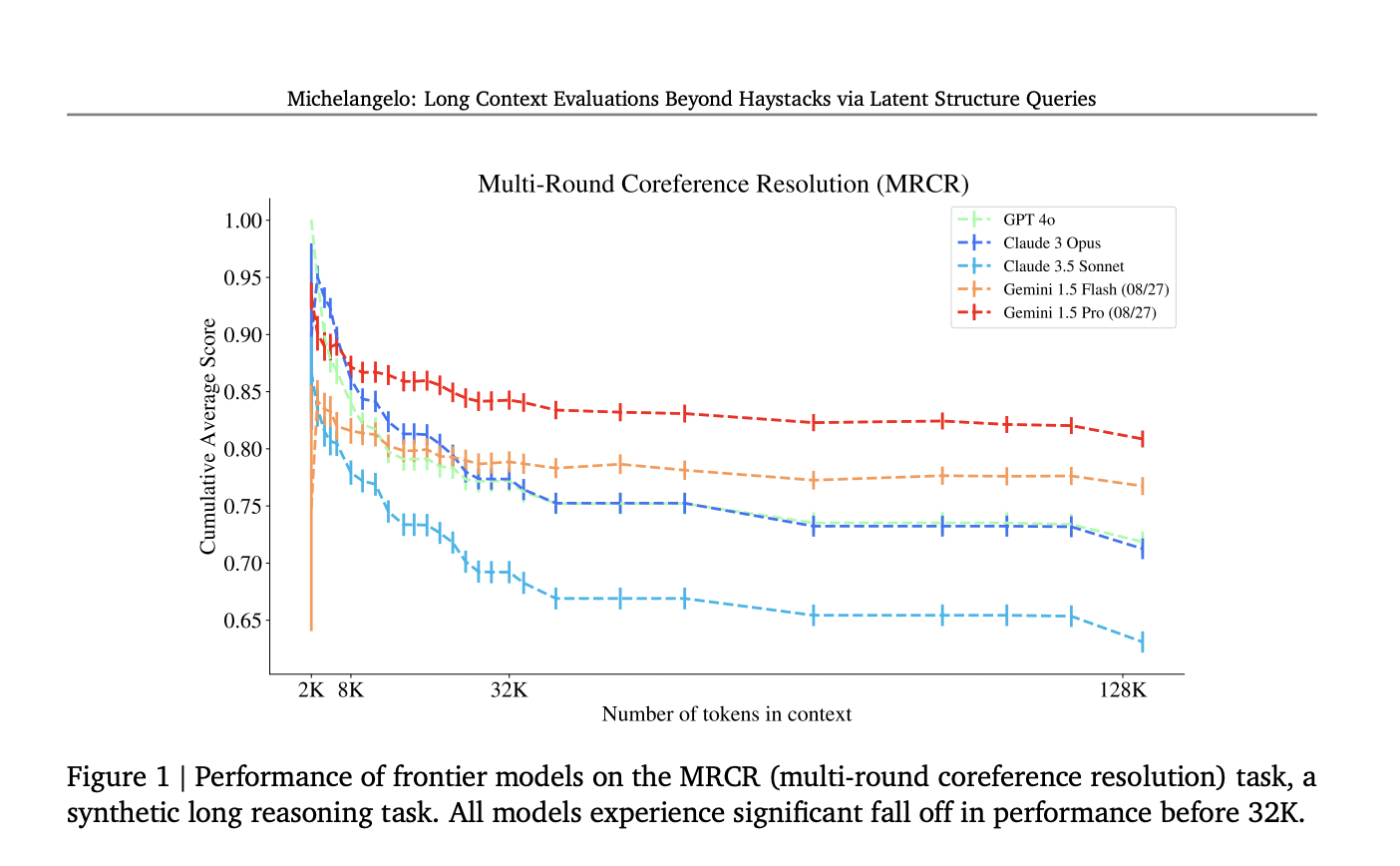
Tasks in Michelangelo Framework
The framework includes tasks like Latent List, Multi-Round Coreference Resolution, and the IDK task to test models’ abilities in handling complex scenarios.
Performance Insights
Michelangelo evaluations reveal performance differences among models like GPT-4, Claude 3, and Gemini, showing varying accuracies in handling long-context tasks.
Advancing AI Reasoning Capabilities
By challenging models with more complex tasks, Michelangelo pushes the boundaries of measuring long-context understanding in large language models.
For more information on Michelangelo and AI solutions, follow us on Twitter and join our Telegram Channel and LinkedIn Group.























