
Introducing MG-LLaVA: Enhancing Visual Processing with Multi-Granularity Vision Flow
Addressing Limitations of Current MLLMs
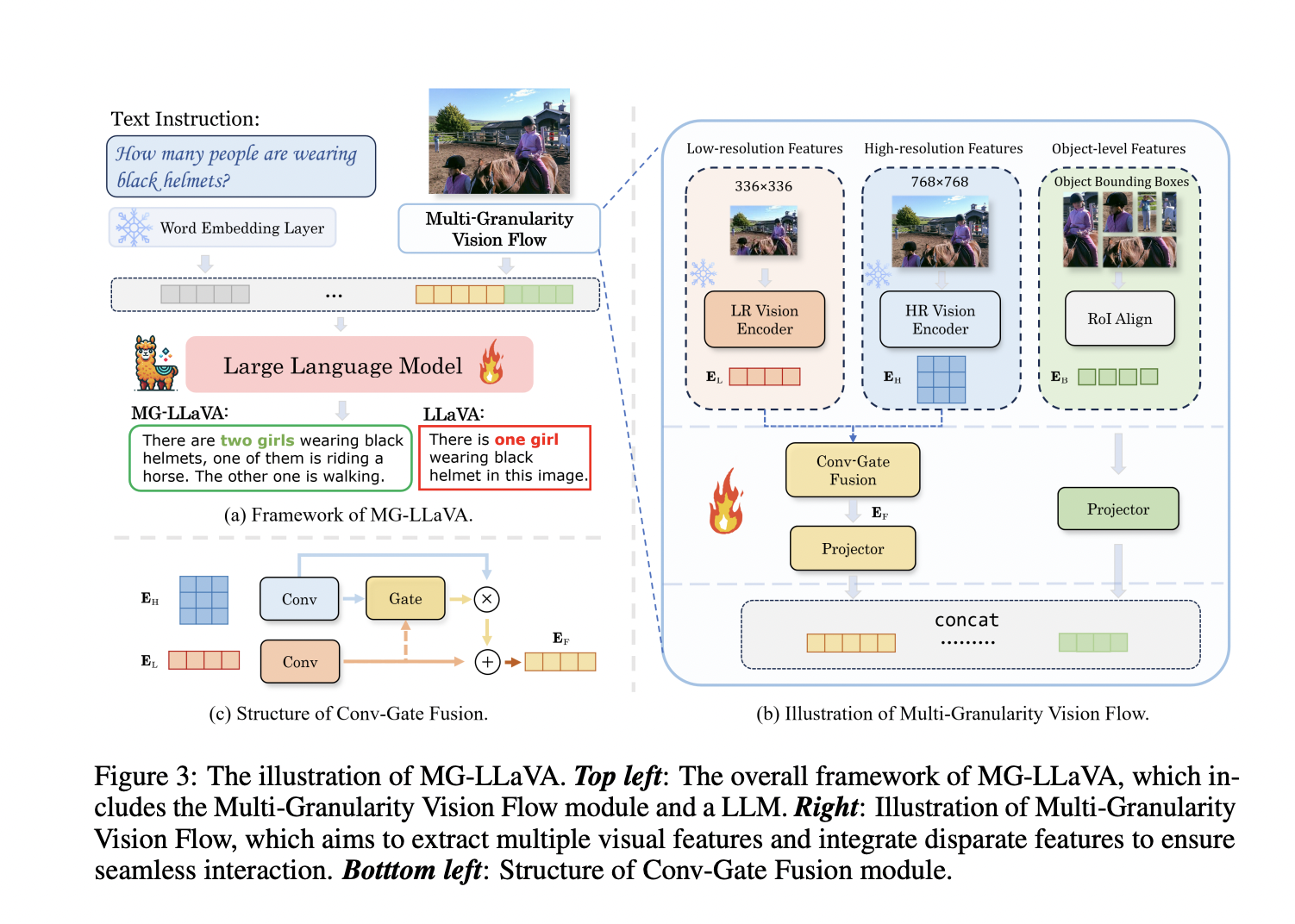
Multi-modal Large Language Models (MLLMs) face challenges in processing low-resolution images, impacting their effectiveness in visual tasks. To overcome this, researchers have developed MG-LLaVA, an innovative model that incorporates a multi-granularity vision flow to capture and utilize high-resolution and object-centric features for improved visual perception and comprehension.
Key Components of MG-LLaVA
The MG-LLaVA framework integrates a multi-granularity vision flow, processing images at different resolutions using a CLIP-pretrained Vision Transformer and ConvNeXt. It also incorporates object-level features using Region of Interest (RoI) alignment and a Conv-Gate fusion network for effective feature integration.
Superior Performance and Practical Value
MG-LLaVA outperforms existing MLLMs, significantly improving perception and visual comprehension across various multimodal benchmarks. Its innovative approach enhances the model’s visual perception and comprehension capabilities, demonstrating superior performance.
Unlocking AI Solutions for Your Business
Discover how MG-LLaVA can redefine your company’s operations and customer engagement. Identify automation opportunities, define KPIs, select AI solutions, and implement gradually to leverage the power of AI. Connect with us for AI KPI management advice and continuous insights into leveraging AI.
For more information, check out the Paper and Project.























