
Practical Solutions for Enhancing Language Model Safety
Addressing Vulnerabilities in Large Language Models
Large Language Models (LLMs) have shown remarkable abilities in various domains but are prone to generating offensive or inappropriate content. Researchers have made efforts to enhance LLM safety through alignment techniques.
Proposed Techniques to Improve LLM Safety
Researchers have introduced innovative methods such as E-RLHF to improve language model alignment and reduce jailbreaking vulnerabilities. These techniques aim to increase safe explanations in the model’s output for harmful prompts without compromising performance on non-harmful ones.
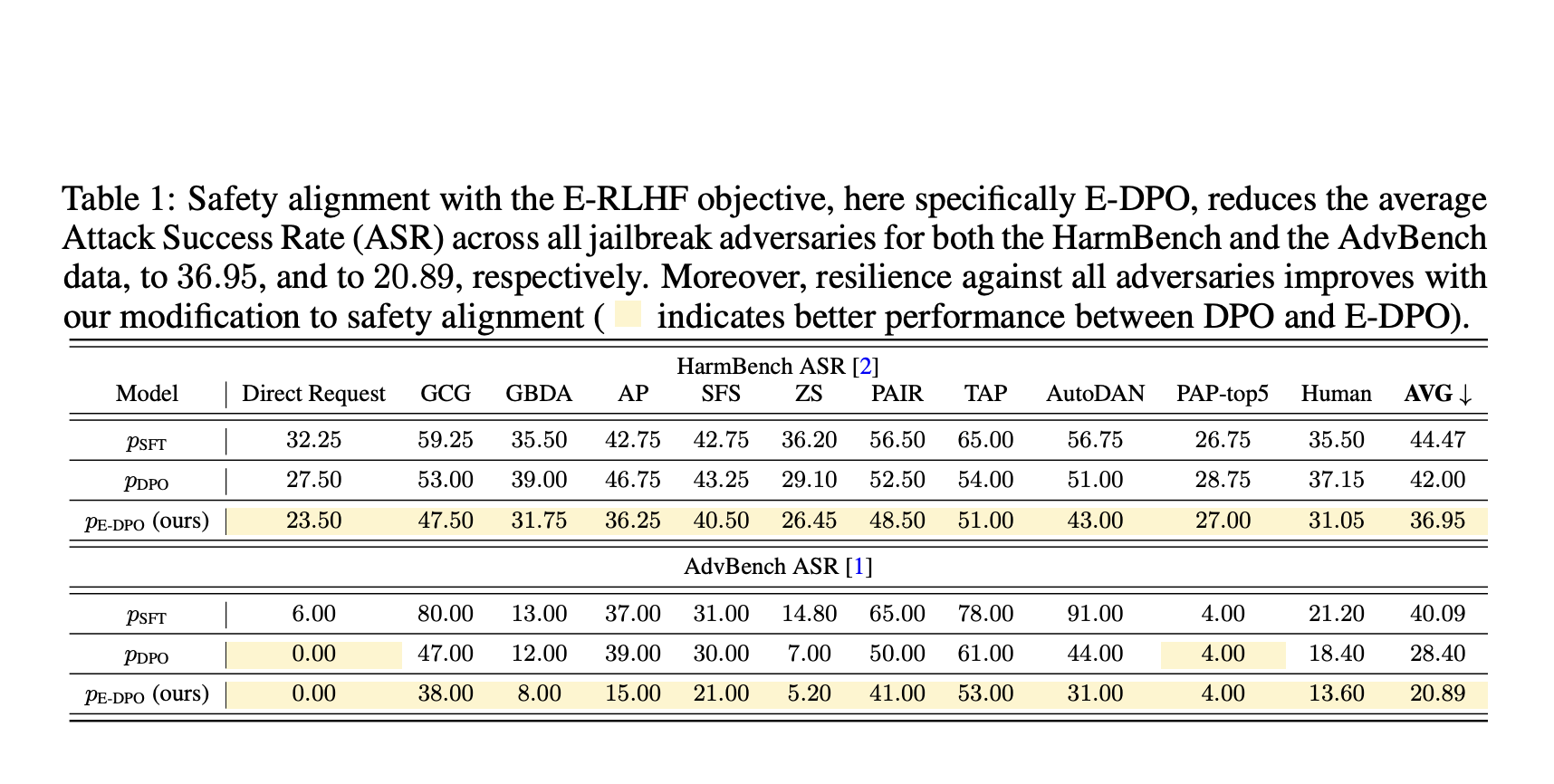
Experimental Results and Conclusion
The experiments demonstrated that the proposed E-DPO method reduced the average Attack Success Rate (ASR) for harmful prompts and improved safety alignment without sacrificing model helpfulness. These advancements contribute to creating safer and more robust language models.
AI Solutions for Business Transformation
Utilizing AI to Redefine Work Processes
Meta AI and NYU Researchers’ E-RLHF proposal offers a competitive advantage for companies looking to evolve with AI. It is essential to identify automation opportunities, define measurable KPIs, select suitable AI solutions, and implement them gradually to achieve impactful business outcomes.
AI-Driven Sales Processes and Customer Engagement
AI can redefine sales processes and customer engagement. Explore AI solutions to transform your business at itinai.com. For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com and stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.












![Exploring Well-Designed Machine Learning (ML) Codebases [Discussion]](https://itinai.com/wp-content/uploads/2025/03/itinai.com_russian_handsome_charismatic_models_scrum_site_dev_96579955-dded-4288-b857-3ee0b72c8d7a_2.png)












