
Challenges with Language Models
Large Language Models (LLMs) perform well in many tasks, but they struggle with multi-step reasoning, especially in complex scenarios like:
- Mathematical problem-solving
- Controlling embodied agents
- Web navigation
Current methods, such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), are often costly and not effective enough for these tasks. There’s a clear need for better solutions.
Introducing OREO: Offline Reasoning Optimization
OREO (Offline REasoning Optimization) is a new solution to enhance the multi-step reasoning of LLMs.
- Developed by researchers from UC San Diego, Tsinghua University, Salesforce Research, and Northwestern University.
- Optimizes LLMs using a unique offline reinforcement learning approach.
- Allows use of unpaired datasets, improving efficiency.
- Enables precise credit assignment, crucial for tasks where few steps lead to success.
Key Features of OREO
- Simultaneously trains policy and value models through optimizing the soft Bellman Equation.
- Offers flexible objectives for various reasoning tasks.
- Implements advanced search techniques during testing, boosting accuracy.
- Learns from failures to improve robustness and adaptability.
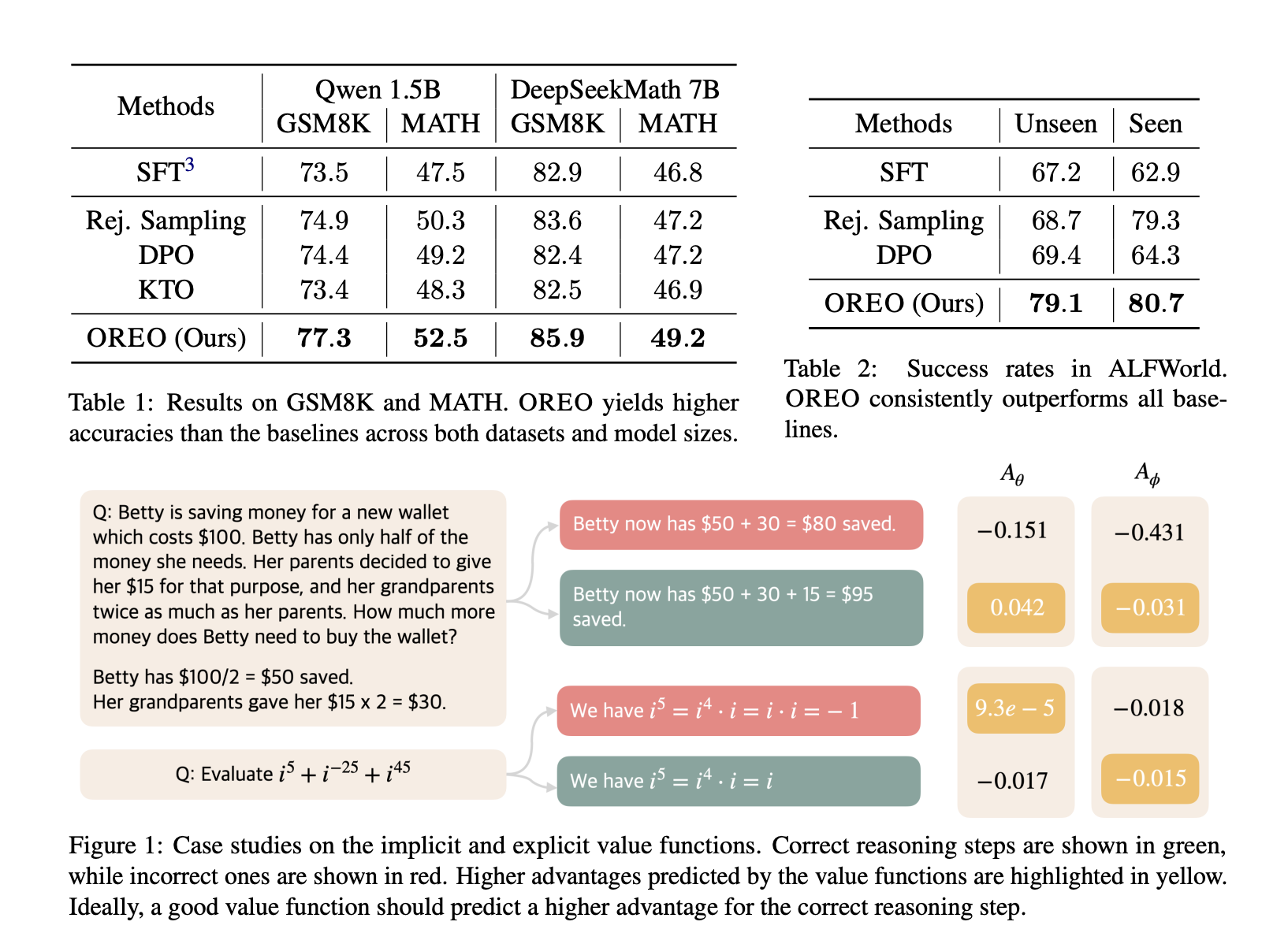
Results and Performance
OREO has shown significant improvements in various benchmarks:
- 5.2% increase in accuracy on GSM8K compared to traditional methods.
- 10.5% improvement on the MATH dataset.
- 17.7% better performance in unseen environments on ALFWorld.
Iterative training enhances OREO’s effectiveness, continually improving its capabilities. Test-time search with OREO results in up to a 17.9% improvement in inference quality.
Conclusion
OREO is a powerful solution for enhancing reasoning in LLMs through offline RL. It addresses existing limitations, providing a viable method for tackling complex reasoning tasks. Its detailed credit assignment and iterative training make it suitable for various applications in AI.
Explore more about OREO and its potential in your organization. Stay connected with our community through:
If you’re looking to enhance your business with AI, reach out to us at hello@itinai.com for advice on AI KPI management.
Discover more about how AI can transform your sales processes at itinai.com.

























